

十一月 2014
source link: http://blog.kongfy.com/2014/11/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
十一月 2014
十一月 2014 发表了 8 篇文章
Twisted和Reactor模式
因为项目关系,接触学习了大名鼎鼎的Python网络编程框架Twised,Twisted是以高性能为目标的异步(event-driven)网络编程框架。

Twisted book
图中是Twisted官方推荐的学习书籍的封面,我觉得封面设计的非常贴切:Twisted就是很多Python(蟒蛇)纠缠在一起。
很多人说Twisted太复杂了,不易于使用,而我并不这么认为。虽然代码流程和朴素的代码流程大相径庭,但复杂性源自于异步编程的思想,而Twisted通过优秀的封装已经极大了减轻了我们的工作量。如果你之前没有接触过异步编程模型,我认为从Twisted入手不失为一个很好的选择。
学习Twisted的最好方式就是阅读Twisted的最新官方指南,有详尽的解释和代码示例,网络上其他的教程都是浪费时间(包括本文,前提是如果本文算得上是教程的话…)。
分类: Python | 2014-11-30 | 491 个字 | 1 Comment
Machine Learning小结(4):主成分分析(PCA)
主成分分析(PCA)是一种通常用来做数据降维的非监督学习算法,下图是数据降维的直观说明:
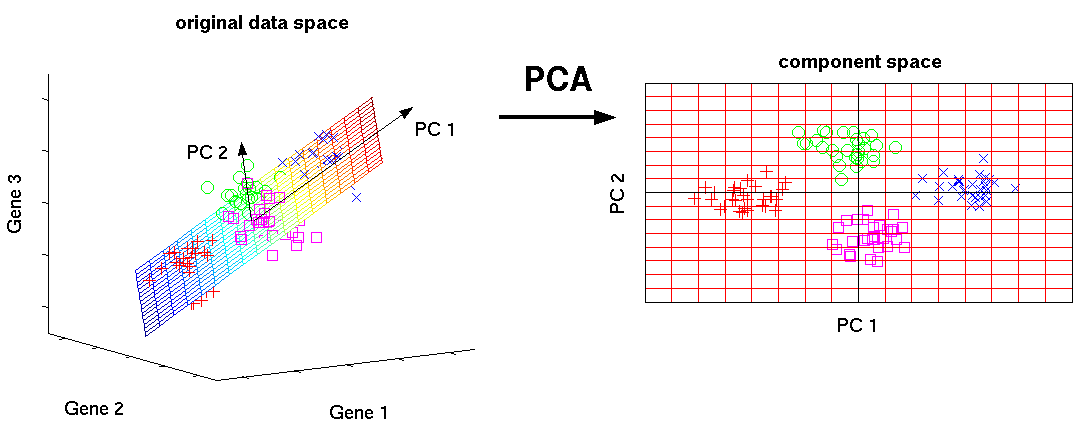
Principal Component Analysis
在PCA中,我们将每个样本看做特征线性空间中的一个向量,左图代表具有三个特征的样本(处于三维空间中,每个特征代表一个维度),通过寻找空间中样本的主成分PC1、PC2,以此建立新的二维线性空间来完成3D到2D的降维。
分类: 机器学习 | 2014-11-28 | 124 个字 | 0 Comments
Machine Learning小结(3):K-means
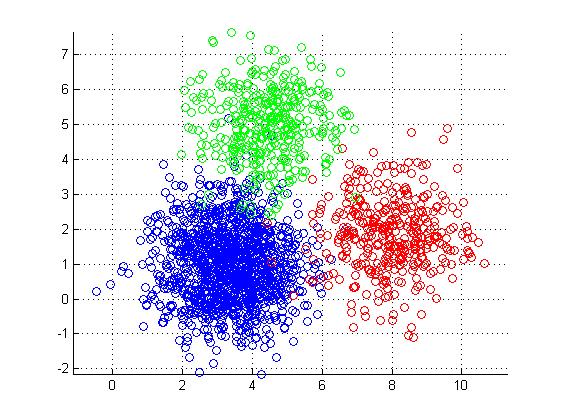
分类: 机器学习 | 2014-11-25 | 149 个字 | 0 Comments
Machine Learning小结(2):SVM
继续总结Ng的课程内容,这次是SVM。Ng在课程中说:
Most people consider the SVM to be the most powerful “black box” learning algorithm.
在实践中,SVM也的确是一种非常流行的“黑盒”学习算法,下图为SVM标志性的概念图:
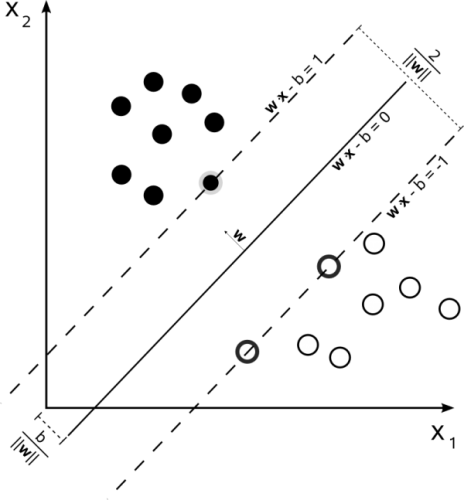
Support Vector Machine
分类: 机器学习 | 2014-11-18 | 423 个字 | 1 Comment
APUE杂记:解释器文件
一个非常常见的Python脚本如下:
一直以来从来没考虑过为什么在脚本的第一行要写上 #!/usr/bin/env python 这样的注释,通常的解释是这样写就知道用什么来解释这个文件了,但是也没有深究为什么。其实这是一个Unix解释器文件的写法。
分类: Linux, Python, 操作系统 | 2014-11-14 | 1,232 个字 | 2 Comments
Linux内核同步

Data protection
Linux内核中有很多同步机制,这篇文章主要总结一下在《Linux Kernel Development》看到的部分内核同步机制,依旧是备忘。
内核同步机制和用户空间的同步机制并不是一一对应的,但是基本的思想都是相同的:保护临界区,只是内核同步机制更适合于在解决内核中的同步问题。先思考下自己的Nanos内核中使用了什么同步机制?Nanos中使用了关中断和信号量机制。
Nanos中的信号量主要用来实现消息传递机制;lock()方法封装了基本的关中断操作,即通过关闭CPU中断(设置IF位)使得不会有线程切换发生,也就保护了临界区。但这在支持多核环境的内核中明显是不适用的,因为每个CPU都有自己的控制寄存器(eflags),关中断仅能保证当前CPU不会发生线程切换,而不能保证其他CPU上运行的线程不会进入临界区,因此,在Linux的SMP环境中需要更多粒度不同、开销不同的同步手段。
注:文中引用的Linux内核代码版本为2.6.32.63
分类: Linux, 操作系统 | 2014-11-13 | 1,077 个字 | 0 Comments
Machine Learning小结(1):线性回归、逻辑回归和神经网络

Coursera上machine learning课程的图标
跟风学习Coursera上Andrew Ng叔的数据挖掘课程已经一个多月了,刚开始在Coursera上看到这门课的时候还有些犹豫,因为研一的时候已经修过学校的数据挖掘课了,那为什么还要再学习这个课程呢?现在想想真是庆幸自己还是选择听听看,原因如下:
- 一年没用数据挖掘,好多知识都忘记了,正好当做复习
- Ng确实很厉害,把看上去非常复杂的理论讲得十分简单清楚,这一定是对问题的本质有很深的理解才能做到的
- lamda的课也是很有水平的,翻翻收藏的ppt,理论功底不可谓不深,但我学艺不精,除去实验外还是不明白在实践中该如何去使用这些工具,Ng的课恰好在这方面是个很好的补充
写到这都和一篇广告软文似的,还是赶紧进入正题吧,趁着脑袋里东西还热乎,赶紧总结一下。PS:本文绝非教程类的文章,而是给自己写的Tips,一则作为学习的记录,二则为以后回忆时方便。如果对这些内容感兴趣,强烈建议直接在Coursera上学习该课程。
分类: 机器学习 | 2014-11-10 | 709 个字 | 3 Comments
广告慎入
继续阅读:→
分类: 杂七杂八 | 2014-11-09 | 125 个字 | 0 Comments
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK