

Estimator a tutorial
source link: https://www.chunyangwen.com/blog/tensorflow/estimator-tutorial.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
介绍 Estiamtor 相关知识。
Tensorflow 在 TensorFlow Estimators: Managing Simplicity vs. Flexibility in High-Level Machine Learning Frameworks 文章中阐述了其在 Tensorflow 基础之上给用户做的一层抽象。主要是对用户屏蔽掉:
- Session 的创建
- 分布式相关的逻辑:
- 包括组网和相关的 Server 构建
本篇文章就是详细解释 Estimator 的具体工作原理。
非 Estimator 基于 Parameter server 架构的分布式学习
本篇文章主要关注的是基于 Parameter server 的数据并行方式下的分布式计算学习。传统的分布式学习大致的逻辑如下:
- 对于 Parameter server:
task_index = 0
ps_hosts = ["a:1001", "b:1011"]
worker_hosts = ["a:1002", "c:1003"]
cluster_def = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# PS server 监听所有 ps 和 worker
session_config = tf.ConfigProto(
device_filters=["/job:ps", "/job:worker"],
)
server = tf.train.Server(
cluster_def,
job_name="ps",
task_index=task_index,
config=session_config,
)
server.join()
- 对于 worker
task_index = 0
ps_hosts = ["a:1001", "b:1011"]
worker_hosts = ["a:1002", "c:1003"]
cluster_def = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# PS server 监听所有 ps 和 worker 自身
session_config = tf.ConfigProto(
device_filters=["/job:ps", "/job:worker/task:%s"%task_index],
)
server = tf.train.Server(
cluster_def,
job_name="worker",
task_index=task_index,
config=session_config,
)
# the server instance will be passed to other functions,
# such as `tf.train.MonitoredTrainingSession`
用户会在上述基础上继续构造数据的 pipeline,构造模型,训练(前向和反向),评估模型,最终导出模型。算法工程师宝贵的时间除了用在建模上,用户需要做很多的工作,很多重复的工作。Estimator 的出现就是期望对用户屏蔽掉更多的底层细节,加速算法的研发和迭代。
Estimator
先看一下 Estimator 的大图。Estimator 主要对外暴露 3 个行为:
- train
- evaluate
- predict
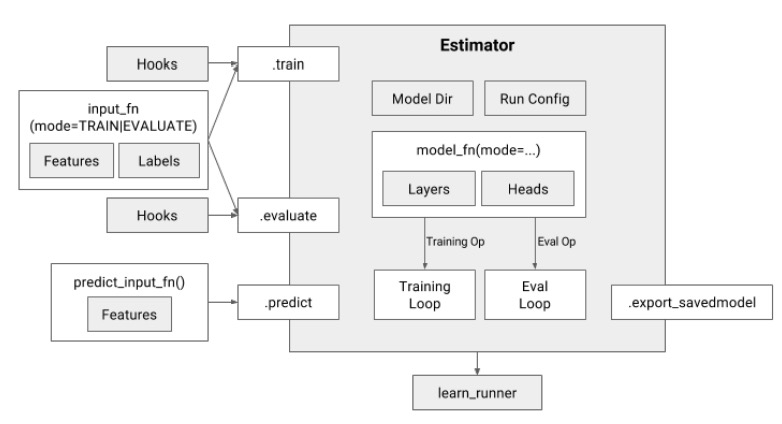
千变万化,最终的接口都会调用到这 3 个接口上,这 3 个接口。这 3 个接口主要对应 3 个 mode:
- tf.estimator.ModeKeys.TRAIN
- tf.estimator.ModeKeys.PREDICT
- tf.estimator.ModeKeys.EVAL
在不同模式下,对返回的 EstimatorSpec 有不同的要求。
主要控制逻辑都依赖 Hooks 。大概有 4 种 hooks
- training_chief_hooks
- training_hooks
- evaluation_hooks
- prediction_hooks
具体接口见:链接
- begin()
- after_create_session(session, coord)
- before_run(run_context)
- after_run(run_context, run_values)
- end(session)
构造 Estimator
先看一个最简单的: y = Wx + b 的线性回归的例子。
import tensorflow as tf
"""
Estimator interface
tf.estimator.Estimator(
model_fn,
model_dir=None,
config=None,
params=None,
warm_start_from=None,
)
"""
class MyEstimator(tf.estimator.Estimator):
"""MyEstimator"""
def __init__(self, model_dir, config=None, params=None):
super(MyEstimator, self).__init__(
self.model_fn,
model_dir=model_dir,
config=config,
params=params,
)
def model_fn(self, features, labels, mode, config):
# 具体的含义见
# https://www.tensorflow.org/api_docs/python/tf/estimator/Estimator#args
optimizer = tf.train.AdamOptimizer()
x = features["x"]
w = tf.Variable(0.1, name="x")
b = tf.Variable(0.1, name="b")
prediction = w * x + b
print("Mode = ", mode)
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode, predictions=prediction)
loss = tf.losses.mean_squared_error(labels, prediction)
train_op = optimizer.minimize(
loss, global_step=tf.train.get_or_create_global_step()
)
if mode == tf.estimator.ModeKeys.EVAL:
metrics = {
"mse": tf.metrics.mean_squared_error(labels, prediction)
}
return tf.estimator.EstimatorSpec(
mode,
predictions=prediction,
eval_metric_ops=metrics,
loss=loss,
)
if mode == tf.estimator.ModeKeys.TRAIN:
return tf.estimator.EstimatorSpec(
mode, predictions=prediction, loss=loss, train_op=train_op,
)
raise ValueError("Not a valid mode: {}".format(mode))
假设上述模型保存为: model.py。在不同 mode 下,其返回的是一个 tf.estimator.EstimatorSpec
tf.estimator.EstimatorSpec(
mode, predictions=None, loss=None, train_op=None, eval_metric_ops=None,
export_outputs=None, training_chief_hooks=None, training_hooks=None,
scaffold=None, evaluation_hooks=None, prediction_hooks=None
)
使用创建的 Estimator
import logging
import os
import random
import subprocess
import tensorflow as tf
from model import MyEstimator
logging.getLogger().setLevel(logging.INFO)
model_dir = "/tmp/temp_model_dir/"
subprocess.check_call("rm -rf %s" % model_dir, shell=True)
estimator = MyEstimator(model_dir)
batch_size = 1
def train_input_fn():
def generator():
for _ in range(10):
datum = random.random()
yield "\t".join(map(str, (datum, datum * 0.8 + 1)))
def parse(line):
fields = tf.decode_csv(line, [[0.0], [0.0]], field_delim="\t")
return {"x": fields[0]}, fields[1]
dataset = tf.data.Dataset.from_generator(
generator, tf.string, tf.TensorShape([])
)
dataset = dataset.map(parse)
return dataset.batch(batch_size)
def serving_input_fn():
feature_tensors = {
"x": tf.placeholder(tf.float32, shape=(None, 1), name="input_x")
}
receiver_tensor = tf.placeholder(
tf.float32, shape=(None, 1), name="output_tensor"
)
return tf.estimator.export.ServingInputReceiver(
feature_tensors, receiver_tensor
)
def predict_input_fn():
def generator():
for _ in range(10):
datum = random.random()
yield "\t".join(map(str, (datum,)))
def parse(line):
fields = tf.decode_csv(line, [[0.0]], field_delim="\t")
return {"x": fields[0]}
dataset = tf.data.Dataset.from_generator(
generator, tf.string, tf.TensorShape([])
)
dataset = dataset.map(parse)
return dataset.batch(batch_size)
estimator.train(train_input_fn)
estimator.evaluate(train_input_fn)
base = os.path.join(model_dir, "test")
result_dir = estimator.export_savedmodel(base, serving_input_fn)
print("Result dir: ", result_dir)
for data in estimator.predict(predict_input_fn):
print(data)
上述文件保存为 main.py。 python main.py 就可以体验下整体的流程。包括训练,验证,打分。
通过上述示例我们可以看到,如果只使用 Estimator 的有限的接口,可以不用操心:
- session 的创建
- 导出 savedmodel 时也不用手动创建 SavedModelBundler
算法工程师转而需要最关心的是:
- 数据怎么生成:相关的 Input_fn
- serving_input_fn: Stackoverflow
- features: model_fn 的输入 placeholders
- receiver_tensors: 模型的输入 placeholders,通过解析后得到 features 相关的
- 模型怎么构建:model.py 中的 model_fn
如果拆开具体的 train/evaluate/predict,其内部本质还是会去创建 Session
- train –
tf.train.MonitoredTrainingSession - evaluate –
MonitoredSession- 不知道为什么要使用 tensorflow.python.training.evaluation 这个模块来完成 evaluate。因为现在 estimator 大部分代码都开始从 tensorflow 中剥离
- predict –
tf.train.MonitoredSession
分布式 Estimator
即使单机可以在内存中存放所有的模型参数,巨大的样本量也会让单机训练逊色。在海量数据的前提下,更多是基于 Parameter Server 的进行的数据并行训练。Tensorflow 较高的版本开始推广 distribute.strategy 。本文不探讨这个,还是基于传统地基于组网信息来进行的分布式训练。
在非 Estimator 模式下,我们只有 ps 和 worker 两种角色。在 Estimator 模式下,会多另外三个角色:
- master: deprecated 官方说不官方支持
- master 节点现在做两件事:worker 0 角色和 evaluator 角色
- master 单节点承担过多的角色
- chief:类似于传统模式下的 worker 0
- evaluator:单独的模型验证节点
- 这个角色会监听 checkpoint 目录,当有新的 checkpoint 产出时,evaluator 会从 checkpoint 恢复参数,从 eval_input_fn 中获取数据进行打分,然后计算 eval_metric_ops 中的值。用户根据结果来判断是否需要导出
所以,在分布式场景中,整个网络中的角色有 4 种:ps, worker,chief 和 evaluator。
- ps,worker 和传统的分布式一致
- chief 充当 worker 0 的角色。但是这个时候 worker 的 task_index 仍然是从 0 开始。不过这里的 worker-0 已经没有特殊的作用。
- evaluator 启动后,负责监听 model_dir 下面的 checkpoint 产出。
驱动分布式训练
import tensorflow as tf
tf.estimator.train_and_evaluate(estimator_instance, train_spec, eval_spec)
主要是调用这个接口来驱动 estimator 的训练。框架会根据 train_spec 和 eval_spec 的内容来控制整个模型的训练流程。多有角色都统一调用此接口,这个接口内部调用到具体的逻辑:Github
tf.estimator.TrainSpec
tf.estimator.TrainSpec(
input_fn, max_steps=None, hooks=None, saving_listeners=None
)
TrainSpec 的内容:
- input_fn: 和之前一致,产出 model_fn 需要的数据内容
- max_steps:是否提前结束任务
- hooks: 派生自 tf.estimator.SessionRunHook
- saving_listeners
tf.estimator.EvalSpec
tf.estimator.EvalSpec(
input_fn, steps=100, name=None, hooks=None, exporters=None,
start_delay_secs=120, throttle_secs=600
)
EvalSpec 的内容:
- input_fn:和之前一致
- steps:提前结束 evaluate
- hooks: 派生自 tf.estimator.SessionRunHook
- exporters:estimator 有提供一些导出的策略控制
- 例如 BestExporter,派生自 tf.estimator.Exporter
import argparse
import json
import logging
import os
import random
import sys
import subprocess
import tensorflow as tf
from model import MyEstimator
logging.getLogger().setLevel(logging.INFO)
model_dir = "/tmp/temp_model_dir/"
subprocess.check_call("rm -rf %s" % model_dir, shell=True)
batch_size = 1
train_number = 1000
test_number = 100
def input_fn(data_size):
def actual_input_fn():
def generator():
for _ in range(data_size):
datum = random.random()
yield "\t".join(map(str, (datum, datum * 0.8 + 1)))
def parse(line):
fields = tf.decode_csv(line, [[0.0], [0.0]], field_delim="\t")
return {"x": fields[0]}, fields[1]
dataset = tf.data.Dataset.from_generator(
generator, tf.string, tf.TensorShape([])
)
dataset = dataset.map(parse)
return dataset.batch(batch_size)
return actual_input_fn
def serving_input_fn():
feature_tensors = {
"x": tf.placeholder(tf.float32, shape=(None, 1), name="input_x")
}
receiver_tensor = tf.placeholder(
tf.float32, shape=(None, 1), name="output_tensor"
)
return tf.estimator.export.ServingInputReceiver(
feature_tensors, receiver_tensor
)
train_spec = tf.estimator.TrainSpec(
input_fn(train_number), max_steps=500, hooks=None
)
eval_spec = tf.estimator.EvalSpec(
input_fn(test_number), steps=50, name=None, hooks=None, exporters=None,
start_delay_secs=0, throttle_secs=0
)
def get_cluster(args):
"""get_cluster"""
cluster = {
"cluster": {
"ps": args.ps_hosts.split(";"),
"worker": args.worker_hosts.split(";"),
"chief": args.chief_hosts.split(";"),
},
"task": {
"type": args.worker_type,
"index": args.worker_index,
}
}
os.environ["TF_CONFIG"] = json.dumps(cluster)
parser = argparse.ArgumentParser()
parser.add_argument("--ps-hosts")
parser.add_argument("--worker-hosts")
parser.add_argument("--chief-hosts")
parser.add_argument("--evaluator")
parser.add_argument("--worker-type", type=str)
parser.add_argument("--worker-index", type=int)
print("Argv: ", sys.argv)
args, _ = parser.parse_known_args()
get_cluster(args)
estimator = MyEstimator(model_dir)
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)
上述文件保存为 main.py
run-dist.sh
#!/bin/sh
file=main.py
mkdir -p logs
FILE=logs/pid.file
if [ -f ${FILE} ]
then
for i in `awk '{print $NF}' ${FILE}`
do
kill -9 $i
done
fi
\rm -rf logs/*
function get_port() {
local avaiable_port=$(python -c \
'from __future__ import print_function;\
import socket; s = socket.socket(); s.bind(("", 0)); \
print(s.getsockname()[1])')
echo $avaiable_port
}
function get_host() {
size=$1
hosts=""
PORT=$(get_port)
for i in `seq ${size}`
do
if [ -z "${hosts}" ]
then
hosts="localhost:"${PORT}
else
hosts=${hosts}";localhost:"${PORT}
fi
PORT=$(get_port)
done
echo ${hosts}
}
function start_tasks() {
type=$1
size=$2
echo "Start ${type}, number: ${size}"
((size-=1))
for i in `seq 0 ${size}`
do
index=$i
python ${file} \
--chief-hosts ${chief_hosts} \
--evaluator-hosts ${evaluator_hosts} \
--ps-hosts ${ps_hosts} \
--worker-hosts ${worker_hosts} \
--worker-type ${type} --worker-index ${index} &> logs/${type}.log.$i &
echo "${type}: "${i}" pid= "$! >> logs/pid.file
done
}
PS_SIZE=1
WORKER_SIZE=2
CHIEF_SIZE=1
EVALUATOR_SIZE=1
ps_hosts=$(get_host ${PS_SIZE})
worker_hosts=$(get_host ${WORKER_SIZE})
chief_hosts=$(get_host ${CHIEF_SIZE})
evaluator_hosts=$(get_host ${EVALUATOR_SIZE})
echo "ps = "${ps_hosts}
echo "worker = "${worker_hosts}
echo "chief = "${chief_hosts}
echo "evaluator = "${evaluator_hosts}
start_tasks "ps" ${PS_SIZE}
echo "Sleep 3s before start worker"
sleep 3s
start_tasks "worker" ${WORKER_SIZE}
start_tasks "evaluator" ${EVALUATOR_SIZE}
type="chief"
index=0
python ${file} \
--chief-hosts ${chief_hosts} \
--evaluator-hosts ${evaluator_hosts} \
--ps-hosts ${ps_hosts} \
--worker-hosts ${worker_hosts} \
--worker-type ${type} --worker-index ${index} &> logs/chief.log.$i
既然可以一键驱动分布式训练,那么 estimator 自身是如何识别自身角色,并且执行对应的逻辑呢?
组网信息依赖环境变量 TF_CONFIG 。
import json
import os
ps_hosts = ["a:1001", "b:1002"]
worker_hosts = ["a:1003", "b:1004"]
chief_hosts = ["a:1004", "b:1003"]
# 对于 ps, worker,chief
## worker task index 从 0 开始
## Evaluator 不能出现在 cluster 中
cluster = {
"cluster": {"ps": ps_hosts, "worker": worker_hosts, "chief": chief_hosts},
"task": {
"index": 0,
"type": "worker", # ps, chief, worker
}
}
# 对于 evaluator 的 cluster,大概如下:
## 当前只能有一个 evaluator
cluster = {
"cluster": {"ps": ps_hosts, "worker": worker_hosts, "chief": chief_hosts},
"task": {
"index": 0,
"type": "evaluator", # ps, chief, evaluator
}
}
os.environ["TF_CONFIG"] = json.dumps(cluster)
主要执行逻辑在:链接
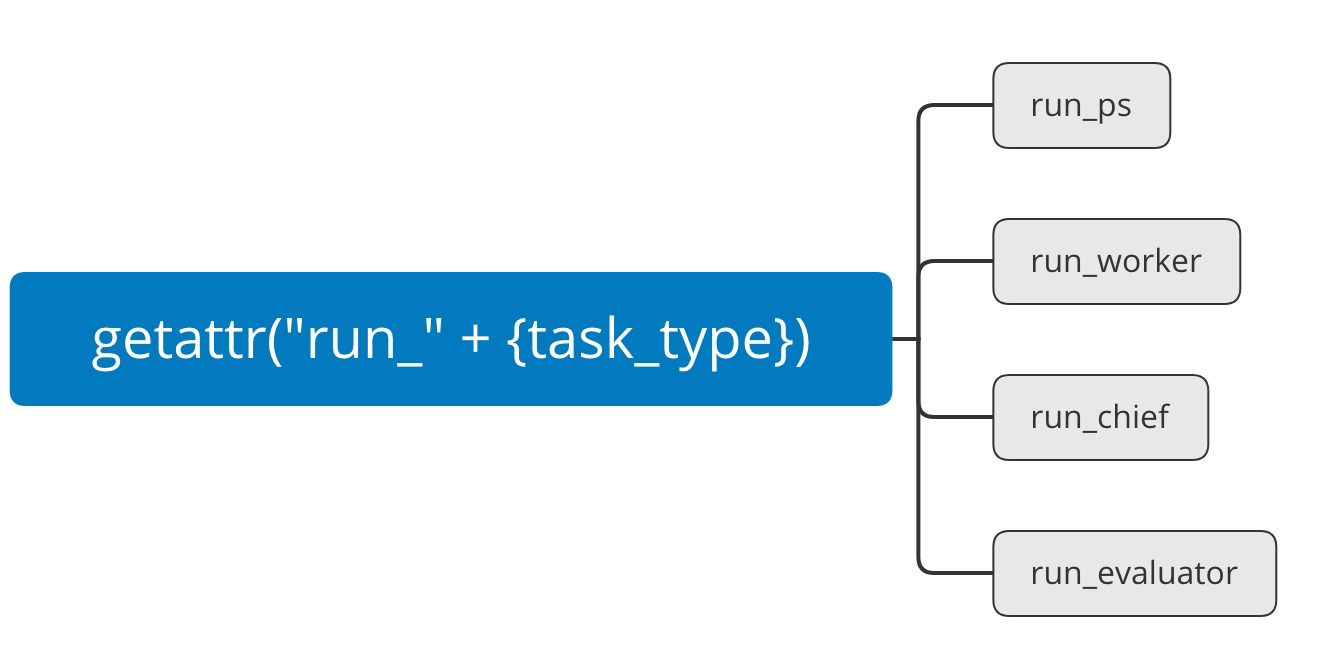
tf.estimator.RunConfig 在构造的时候会从 TF_CONFIG 中去解析,然后找到正确的逻辑,最后执行如下逻辑之一:
- run_ps
- run_worker
- run_chief
- run_master
- 会额外启动一个 Evaluator
- run_evaluator
TFOperator
社区的 TFOperator 组网信息是 deprecated 的 master + ps + worker。这种会存在 master 任务过重的问题。虽然它是启动一个子线程来进行模型验证。但是是单机加载模型,容易受内存影响。Estimator 本质是根据 TF_CONFIG 来判断的,所以我们只要在启动 Estimator 前更改掉这个变量即可。
多个角色之间同步问题
Evaluator 是单独启动的,它只是监听 model_dir 是否有新的 checkpoint 产出,并且进行验证。所有 evaluator 的退出过早会导致模型没有验证完,所以需要在退出时有某种同步。例如 chief 产出模型后,需要确认其产出的 checkpoint 确实被验证。
Evaluator 不退
Evaluator 现在唯一的退出条件是 global_step > max_steps。所以 max_steps 设置的不合理,不加同步控制的话, Evaluator 也不会主动退出。而且如果 evaluator 主动退出,也会导致新产出的 checkpoint 没有得到验证
分布式的 prediction
Estimator 支持分布式的训练和验证。但是现在打分逻辑并没有分布式化。可以参考这里的回答:Stackoverflow.
其核心思想是我们仍然尝试去复用 estimator 的中的部分逻辑,但是在创建 session 时,需要创建 MonitoredTrainingSession。这样就可以依赖 checkpoint 路径自动去加载模型。
- 手动启动 server:如果不启动的话,会出现假死的现象
- 重新覆盖掉 estimator 的 predict
import argparse
import json
import logging
import os
import random
import sys
import subprocess
import six
import tensorflow as tf
from tensorflow.core.protobuf import config_pb2
from tensorflow.python.training import server_lib
from tensorflow.python.training import training
from tensorflow.python.framework import random_seed
from tensorflow.python.eager import context
from tensorflow_estimator.python.estimator import model_fn as model_fn_lib
from tensorflow_estimator.python.estimator import estimator
from tensorflow.python.framework import ops
from model import MyEstimator
logging.getLogger().setLevel(logging.INFO)
model_dir = "/tmp/temp_model_dir/"
batch_size = 1
train_number = 1000
test_number = 100
def input_fn(data_size):
def actual_input_fn():
def generator():
for _ in range(data_size):
datum = random.random()
yield "\t".join(map(str, (datum, datum * 0.8 + 1)))
def parse(line):
fields = tf.decode_csv(line, [[0.0], [0.0]], field_delim="\t")
return {"x": fields[0]}, fields[1]
dataset = tf.data.Dataset.from_generator(
generator, tf.string, tf.TensorShape([])
)
dataset = dataset.map(parse)
return dataset.batch(batch_size).make_one_shot_iterator().get_next()
return actual_input_fn
def get_cluster(args):
"""get_cluster"""
cluster = {
"cluster": {
"ps": args.ps_hosts.split(";"),
"worker": args.worker_hosts.split(";"),
"chief": args.chief_hosts.split(";"),
},
"task": {
"type": args.worker_type,
"index": args.worker_index,
}
}
os.environ["TF_CONFIG"] = json.dumps(cluster)
def run_std_server(config):
if config.session_config is None:
session_config = config_pb2.ConfigProto(log_device_placement=False)
else:
session_config = config_pb2.ConfigProto(
log_device_placement=False,
gpu_options=config.session_config.gpu_options,
)
server = server_lib.Server(
config.cluster_spec,
job_name=config.task_type,
task_index=config.task_id,
config=session_config,
start=False,
protocol=config.protocol,
)
server.start()
return server
def hook_predict(args, config):
# Override estimator predict
def predict(
self,
input_fn,
predict_keys=None,
hooks=None,
checkpoint_dir=None,
yield_single_examples=True,
):
"""Arguments are same with Estimator.predict"""
with context.graph_mode():
hooks = estimator._check_hooks_type(hooks)
# Check that model has been trained.
if not checkpoint_dir:
raise ValueError("No checkpoint_dir")
with ops.Graph().as_default() as g, g.device(self._device_fn):
random_seed.set_random_seed(self._config.tf_random_seed)
self._create_and_assert_global_step(g)
features, input_hooks = self._get_features_from_input_fn(
input_fn, model_fn_lib.ModeKeys.PREDICT
)
estimator_spec = self._call_model_fn(
features,
None,
model_fn_lib.ModeKeys.PREDICT,
self.config,
)
predictions = self._extract_keys(
estimator_spec.predictions, predict_keys
)
all_hooks = list(input_hooks)
all_hooks.extend(hooks)
all_hooks.extend(
list(estimator_spec.prediction_hooks or [])
)
with training.MonitoredTrainingSession(
is_chief=args.worker_type=="chief",
master=config.master,
checkpoint_dir=checkpoint_dir,
config=config.session_config,
) as mon_sess:
while not mon_sess.should_stop():
preds_evaluated = mon_sess.run(predictions)
if not yield_single_examples:
yield preds_evaluated
elif not isinstance(predictions, dict):
for pred in preds_evaluated:
yield pred
else:
for i in range(
self._extract_batch_length(preds_evaluated)
):
yield {
key: value[i]
for key, value in six.iteritems(
preds_evaluated
)
}
estimator.Estimator.predict = predict
parser = argparse.ArgumentParser()
parser.add_argument("--ps-hosts")
parser.add_argument("--worker-hosts")
parser.add_argument("--chief-hosts")
parser.add_argument("--evaluator")
parser.add_argument("--worker-type", type=str)
parser.add_argument("--worker-index", type=int)
print("Argv: ", sys.argv)
args, _ = parser.parse_known_args()
get_cluster(args)
user_estimator = MyEstimator(model_dir)
server = run_std_server(user_estimator.config)
if args.worker_type == "ps":
server.join()
else:
hook_predict(args, user_estimator.config)
kwargs = {
"checkpoint_dir": model_dir,
}
for data in user_estimator.predict(input_fn(10), **kwargs):
print(data)
#!/bin/sh
killed_exit=$1
file=main_dist.py
mkdir -p logs
FILE=logs/pid.file
if [ -f ${FILE} ]
then
for i in `awk '{print $NF}' ${FILE}`
do
kill -9 $i
done
fi
[[ ! -z ${killed_exit} ]] && exit 0
\rm -rf logs/*
function get_port() {
local avaiable_port=$(python -c \
'from __future__ import print_function;\
import socket; s = socket.socket(); s.bind(("", 0)); \
print(s.getsockname()[1])')
echo $avaiable_port
}
function get_host() {
size=$1
hosts=""
PORT=$(get_port)
for i in `seq ${size}`
do
if [ -z "${hosts}" ]
then
hosts="localhost:"${PORT}
else
hosts=${hosts}";localhost:"${PORT}
fi
PORT=$(get_port)
done
echo ${hosts}
}
function start_tasks() {
type=$1
size=$2
echo "Start ${type}, number: ${size}"
((size-=1))
for i in `seq 0 ${size}`
do
index=$i
python ${file} \
--chief-hosts ${chief_hosts} \
--evaluator-hosts ${evaluator_hosts} \
--ps-hosts ${ps_hosts} \
--worker-hosts ${worker_hosts} \
--worker-type ${type} --worker-index ${index} &> logs/${type}.log.$i &
echo "${type}: "${i}" pid= "$! >> logs/pid.file
done
}
PS_SIZE=1
WORKER_SIZE=2
CHIEF_SIZE=1
EVALUATOR_SIZE=1
ps_hosts=$(get_host ${PS_SIZE})
worker_hosts=$(get_host ${WORKER_SIZE})
chief_hosts=$(get_host ${CHIEF_SIZE})
echo "ps = "${ps_hosts}
echo "worker = "${worker_hosts}
echo "chief = "${chief_hosts}
start_tasks "ps" ${PS_SIZE}
echo "Sleep 3s before start worker"
sleep 3s
start_tasks "worker" ${WORKER_SIZE}
type="chief"
index=0
python ${file} \
--chief-hosts ${chief_hosts} \
--evaluator-hosts ${evaluator_hosts} \
--ps-hosts ${ps_hosts} \
--worker-hosts ${worker_hosts} \
--worker-type ${type} --worker-index ${index} &> logs/chief.log.$i
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK