

用 Venn Diagram 理解多元线性回归的 OLS 估计
source link: https://zhuanlan.zhihu.com/p/264377667
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

摘要
Venn diagram 为理解多元回归模型的 OLS 估计提供了直观思路。通过它,人们很容易搞懂共线性、遗漏变量造成的问题,并直观的感受 R-squared、回归系数估计以及其误差的高低。
01 引言
线性回归模型以及其估计方法 OLS 在实证资产定价中发挥了重要的作用。例如传统 Fama-French 三因子时序回归模型以及 Fama and MacBeth (1973) 截面回归都是这样的例子。相信各位小伙伴对此都不陌生。
今天这篇小文将从一个非常直观的角度解释多元线性回归背后的机制,并探讨常见的多重共线性以及遗漏变量将会对回归系数估计造成何种影响。这个直观的角度就是 Venn Diagram(韦恩图) 。必须强调的是,Venn diagram 的目的是提供直观理解,加深人们对 OLS 估计机理的认知。
Venn Diagram 由英国数学家 John Venn 发明,用于展示在不同的事物群组(集合)之间的数学或逻辑联系。
A Venn diagram, also called primary diagram, set diagram or logic diagram, is a diagram that shows all possible logical relations between a finite collection of different sets.
例如下面这组图就展示了两个集合之间的不同关系(出处:wikipedia):

那么 Venn diagram 和 OLS 又有什么关系?将 Venn diagram 用于解释多元线性回归可以追溯到 Cohen and Cohen (1975),之后 Kennedy (1981, 2002)、Ip (2001) 等在其基础上又有了大量的拓展。此外,邱嘉平教授的《因果推断实用计量方法》一书对 Venn diagram 也有涉及。
下面就先来说说基本要素。
02 基本要素
当使用 Venn diagram 研究回归问题时,每个变量可被表示成一个圆圈,而圆圈的面积则用来表示每个变量的方差 —— 面积越大表示方差越大;而两个圆圈重叠的部分则表示两变量相互关联的部分,即协方差。 以上就是研究的基本要素。
以下图为例,考虑解释变量 x 和被解释变量 y。两个圆圈分别表示它们各自的方差,重叠的部分 B 则表示它们共同运动的部分,即 x 和 y 的协方差。
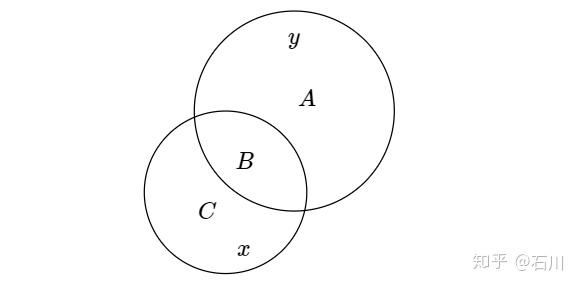
依照图中信息,y 的方差 var(y) 为 A + B 的面积;x 的方差 var(x) 为 B + C 的面积;x 和 y 的协方差 cov(x, y) 为 B 的面积。带着这些要素,马上来看单一解释变量的情况。
03 单个解释变量
假设 y 和 x 满足以下线性回归模型:
通过 OLS 对其进行估计可得(这里我们只关心
的回归系数 b 的估计):
对应上一节的 Venn diagram 中的定义,马上可以看出 b 的估计为 B 的面积和 B + C 面积之比:
结合 Venn diagram 和 b 估计量的定义可以总结出以下三点:
- 在 OLS 估计时,x 和 y 重叠的部分 B 将被用来估计 x 的系数 b;如果 B 所包含的信息仅和 x 有关(而和其他解释变量无关;多元回归问题将在下一节说明),那么使用这部分信息得到的 b 的估计就是无偏的;
-
若 B 的面积越大,则用来估计回归系数 b 的信息越多,因此
的 standard error 就越小(如何通过 Venn diagram 中不同部分的面积推断 standard error 的大小将在多元回归中说明)。
- 图中,A 是 x 无法解释的 y 的波动,即回归模型中扰动项 e 的方差。
以上就是一元回归的直观理解。
04 多元回归
下面来看多元回归的情况。多元回归要比一元回归有(fu)趣(za)的多。
为了便于理解,考虑两个不完全独立的解释变量
和
,以及被解释变量 y。它们之间的关系满足以下线性回归模型:
当使用 Venn diagram 时,它们的关系如下图所示。
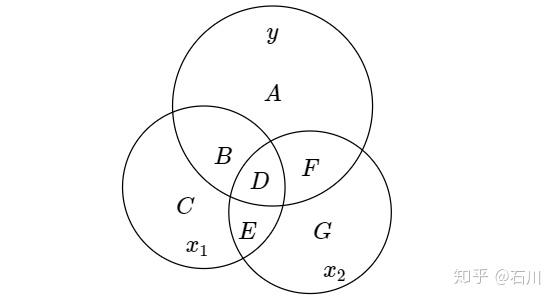
从图中可知,
和 y 相关联的部分可通过 B + D 的面积表示,而
和 y 相关联的部分则可由 F + D 表示。 而这其中 D 是共有的部分,即 D 部分表示的 y 的波动是由
和
共同驱动的。
那么问题来了,在 OLS 估计
和
时,应该用到 Venn diagram 中的哪部分信息?得到的估计又是否是无偏的?考虑以下三个选项,你认为哪个是正确的?
-
使用 B + D 包含的信息估计
的系数
、F + D 包含的信息估计
的系数
;
-
通过某种巧妙的方法分割 D 的信息,使之一部分和 B 一起估计
-
舍弃 D,仅使用 B 的信息来估计
怎么样?思考一下。

如果你选择了 3,那么恭喜你!1 和 2 之所以不对,恰恰是 因为 D 部分表示的 y 的波动是由 x_1 和 x_2 共同驱动的,因此难以分清两个解释变量各自的贡献;D 又被称为被污染的信息。
此外,当仅使用 B 和 F 分别估计
和
时,由于 B 和
无关,F 和
无关,因此得到的
和
的估计也都是无偏的。OLS 背后的数学原理也恰恰保证了这一点。如果用 Venn diagram 图中的部分表示,则
和
的估计量分别为:
除此之外,和一元回归类似,在上图中 A 的部分代表 y 中无法被
和
解释的部分,因此它是扰动项 e 的方差。此外,通过 Venn diagram 也可以方便的看出可决系数 R-squared 的定义,它是 B、D、F 三部分面积之和与 A、B、D、F 四部分面积之和之比:
有的小伙伴可能已经注意到了,虽然在估计回归系数时舍弃了 D,但是在计算 R-squared 时却没有。这是因为 D 是两个解释变量共同解释 y 的部分。虽然我们无法分清每个变量贡献了多少,但它们作为一个整体依然对解释 y 的波动有贡献,因此在计算 R-squared 时应考虑 Venn diagram 中 D 的面积。
回到我们关注的问题 —— 实证资产定价,仅仅得到回归系数的估计是不够的,很多时候都要知道估计的 standard error,才能进行检验。由 OLS 性质可知,对于回归系数
,其估计值的方差可由下式决定:
式中的分子是模型中随机扰动项的方差(实际中代入样本方差即可,再对上式开根号就得到 standard error)。
为用
对其他所有
回归的可决系数;
越高说明
和其他解释变量相关性越高。
最后,
是变量
的 total sample variation(不难看出它和
的方差就差一个系数):
的表达式说明, 当
自身的波动越大且/或
和其他解释变量的相关性越低时,其估计误差越小。
由于 Venn diagram 中的面积表示方差或协方差,且结合前述 R-squared 的定义,就可以通过 Venn diagram 中的元素清晰的反映出
的表达式。举例来说,在本节考虑的二元回归模型中,
的回归系数估计
的方差如下图所示。
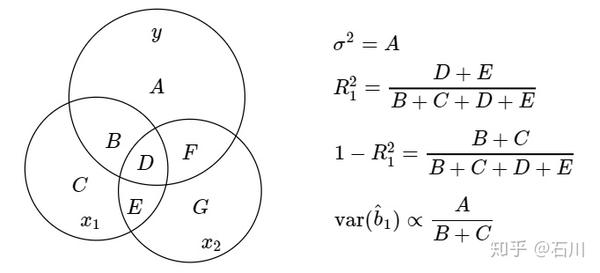
显然,当 B + C 的面积非常小时,
就会非常大。什么时候 B + C 会非常小呢?解释变量之间存在高度相关时就会出现这种情况。
下面就来讨论这一问题。
05 高度共线性
多元回归中,经常遇到的问题就是解释变量之间高度相关。以下面两图为例,左边是一个
和
有正常关系的 Venn diagram,右侧则是
和
高度共线性的 Venn diagram。二者的相关性体现在
和
的圆圈重叠部分非常大(即 D + E 的面积非常大)。
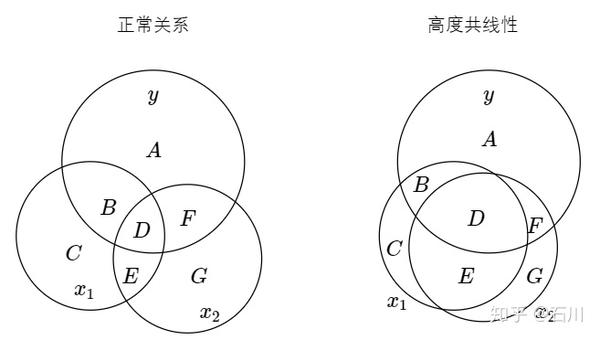
由 OLS 可知,由于 D 部分是被污染的信息,因此在估计
和
时被舍弃了。如果 D 的面积非常大(解释变量高度相关),那么剩余的面积(上图中的 B 和 F)就会很少,相当于只有很少的信息用来估计
和
,因此可想而知估计误差就会更高。 在极端情况下,当
和
完全共线性时(即代表它们的两个圆圈完全重合),则 B 和 F 均消失,这时将没有任何信息用来估计
和
。
依照上一节给出的
的直观解释,
和
分别满足:
当存在高度共线性时,B、C、F、G 都会变得非常小,因此上述中的分母就会非常小,导致很大的方差。但需要强调的是, 即便存在高度共线性,但上述 OLS 中
和
的估计也是无偏的,
因为依然仅使用了 B 和 F 来分别估计,而没有用到被污染的信息 D。
另一方面,由 R-squared 的定义可知,在计算它时无需剔除 D。因此,这将会造成一个非常有意思的现象, 即当高度共线性存在时,R-squared 很大(即所有解释变量有很好的共同解释力),但每个解释变量的回归系数却都不显著(因为 standard error 太大)。 在实际数据中,如果发现这个现象,很可能是多重共线性惹的祸。
既然谈到相关性,再捎带手聊一下正交化的问题。假设使用
对
回归,求出残差作为正交化之后的
,记为
。下图中右侧 Venn diagram 中的红色“月牙”就是
,绿色是
。
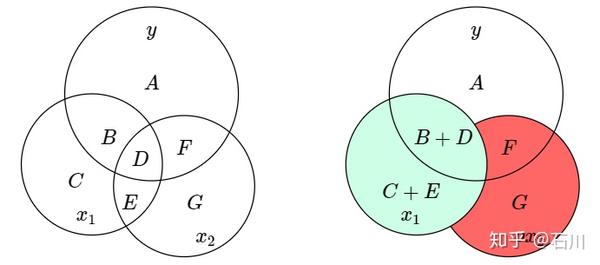
从 Venn diagram 不难看出,当不正交化时(上方左图),会使用 B 和 F 分别估计
和
;而当对
正交化之后(上方右图),则会使用 B + D 估计
、使用 F 来估计
。因此对
正交化对
的估计是没有影响的,但其依然会影响
的估计结果。以下是一个简单的例子说明上述这一点。
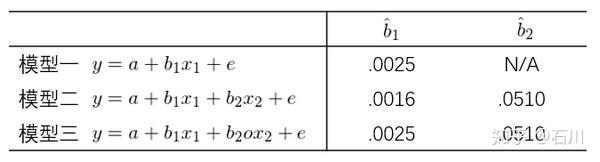
由于正交化后的
和
不相关(体现在图上就是两者不相交),因此模型一(仅有
)和模型三(包含
和
)中
的估计值是一样的。另一方面,由于正交化
不改变
的估计,因此在模型二(包含
和
)和三中,
的估计值是一样的。最后,由于在模型三中,
被正交化,因此 B + D 被用来估计
,因此相比模型二,其估计值的 standard error 更低。
06 遗漏变量
通过下图解释遗漏变量问题。假设解释变量
、
以及被解释变量 y 的关系如 Venn diagram 所示,并考虑图中两个模型,其中模型一因为仅考虑了
,因此存在遗漏变量问题。
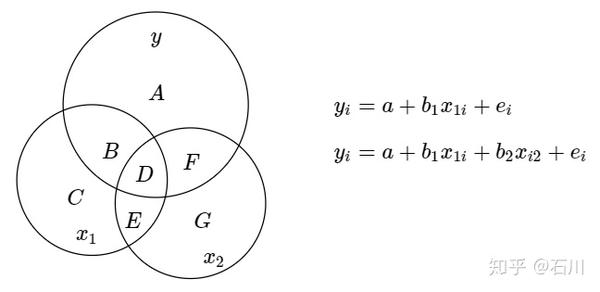
对
的系数
来说,在这两个模型中,其 OLS 估计分别为:
由于遗漏变量,第一个模型错误的使用 D 所包含的信息(被污染的信息),因此 第一个模型中
的估计是有偏的
(例外是
和
不相关,则 D 不存在)。然而,遗漏变量也并非都是缺点,其优点(姑且算作优点)是由于更多的信息(D)被用来估计
,因此它的 standard error 更低。
另一点值得说明的是,当遗漏
时,由 Venn diagram 可知,图中 A + F 的面积被错误的当作扰动项 e 的方差;而实际当同时使用
和
时,其方差应为 A。 遗漏变量造成扰动项 e 的方差被高估。
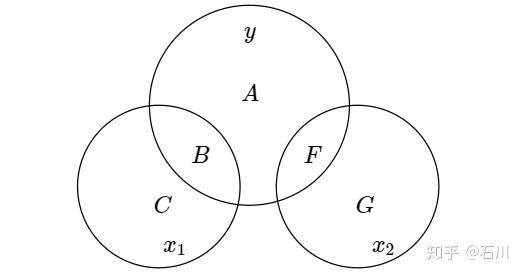
最后,若
和
不相关时(下图;解释变量不相关体现在 Venn diagram 上代表
和
的两个圆圈没有重叠),则遗漏
不会对
的估计造成影响。这是因为无论是 y 仅对
回归还是同时对
和
回归,在估计
时用到的均是 B 的信息。由于
和
不相关,因此区域 B 不受
的影响。
07 结语
通过利用 Venn diagram,人们很容易搞懂共线性、遗漏变量造成的问题,并直观的感受 R-squared、回归系数估计以及其误差的高低。
照例总结一下: 当存在共线性时,估计依然是无偏的,但是 standard error 会变大;而当存在遗漏变量且遗漏的变量和现有的解释变量相关时,那么估计将会是有偏的、但 standard error 会降低,且 y 的扰动项的方差会被高估。
不过 Venn diagram 也绝非无所不能。 比如图中重叠的部分仅仅表示两个变量之间存在相关性,但它无法说明是正相关还是负相关。
无论如何,Venn diagram 为加深人们对多元回归模型的 OLS 估计的理解提供了非常直观的思路,是一个非常好用的思考工具。希望本文的介绍能带给你这种体会。
参考文献
- Cohen, J. and P. Cohen (1975). Applied Multiple Regression/Correlation Analysis for the Behavioral Science . Hillside, NJ: Lawrence Erlbaum Associates.
- Fama, E. F. and J. D. MacBeth (1973). Risk, return, and equilibrium: Empirical tests. Journal of Political Economy 81 (3), 607 – 636.
- Ip, E. H. S. (2001). Visualizing multiple regression. Journal of Statistics Education 9 (1).
- Kennedy, P. E. (1981). The “Ballentine”: A graphical aid for econometrics. Australian Economic Papers 20 (37), 414 – 416.
- Kennedy, P. E. (2002). More on Venn Diagrams for regression. Journal of Statistics Education 10 (1).
- 邱嘉平 (2020). 因果推断实用计量方法 . 上海财经大学出版社.
免责声明: 文章内容不可视为投资意见。市场有风险,入市需谨慎。
原创不易,请保护版权。如需转载,请联系获得授权,并注明出处。已委托“维权骑士”( 维权骑士-版权保护 版权知识 原创检测 识别字体 著作权登记 ) 为进行维权行动。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK