

处理器感知线程管理系统 · OSDI 2018 - 面向信仰编程
source link: https://draveness.me/papers-arachne/?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

处理器感知线程管理系统 · OSDI 2018
2020-06-10 看看论文 OSDI 系统设计 调度器 线程管理 Linux
『看看论文』是一系列分析计算机和软件工程领域论文的文章,我们在这个系列的每一篇文章中都会阅读一篇来自 OSDI、SOSP 等顶会中的论文,这里不会事无巨细地介绍所有的细节,而是会筛选论文中的关键内容,如果你对相关的论文非常感兴趣,可以直接点击链接阅读原文。
本文要介绍的是 2018 年 OSDI 期刊中的论文 —— Arachne: Core-Aware Thread Management1,这篇论文通过引入处理器感知的线程管理器 Arachne2 提高应用程序的性能,通过在 Memcached 中引入新的线程管理器,我们可以将 Memcached 的吞吐量提高 37%、降低 10 倍的尾延迟并且在与其他应用程序混合部署时也几乎不会带来性能上的损耗。今天我们来看一看论文中基于处理器感知的线程管理器如何帮助应用程序实现低延迟和高吞吐量。
想要同时实现低延迟和高吞吐量不是一件简单的事情,在传统的线程管理或者协程管理器中,上层的应用程序不清楚底层的调度策略,应用程序自己无法决定会跑在哪个 CPU 上。因为大多数的场景不需要考虑极端的性能,代码的可维护性和可读性相比更加重要,这种关注点分离的设计方式能够降低应用程序的复杂性,所以它能够为开发者提供便利。
应用程序想要实现低延迟和高吞吐量就一定要通过虚拟资源管理它们的并行性,而现在它们没有办法告诉操作系统需要多少 CPU 资源,也无法直接确定线程和 CPU 之间的绑定关系。想要实现低延迟和高吞吐量,每个应用程序都应该能够根据负载动态决定需要多少 CPU 资源并且可以控制线程和 CPU 的绑定关系。
处理器感知线程管理会为应用程序提供 CPU 等信息,将对 CPU 的部分控制权开放给应用开发者以满足应用程序在性能上的需求、不过因为 Linux 等操作系统没有直接提供易用的接口,所以 Arachne 使用了如下图所示的架构实现处理器感知的线程管理,整个系统不需要修改操作系统内核,它依赖操作系统提供的接口实现处理器感知,也可以与不使用 Arachne 的应用程序一起运行:
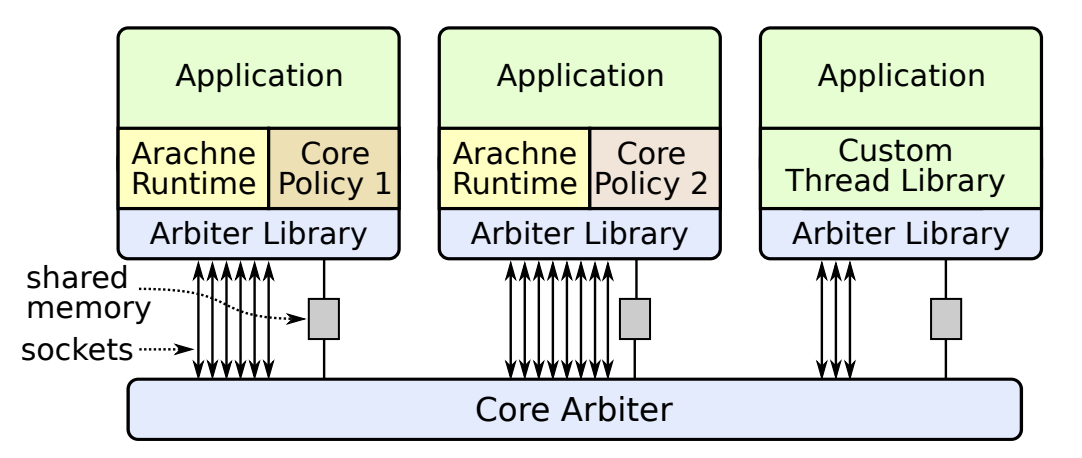
图 1 - Arachne 架构
Arachne 中包含了三个重要的组件,分别是仲裁者、运行时和策略,其中仲裁者是运行在 Linux 上的守护进程,所有使用 Arachne 的应用程序都会利用它提供的运行时库通过 Socket 与守护进程通信,我们将依次介绍这三个组件的作用和原理。
核心仲裁者(Core Arbiter)是 Arachne 的核心组件,它是应用程序和操作系统的中间层,主要负责控制系统中的 CPU 并将这些资源合理地分配给不同的应用程序,该系统包含三个特点:
- 在用户态基于 Linux 的机制实现了 CPU 管理;
- 可以与不使用 Arachne 的应用程序同时存在;
- 使用协作式的方法管理内核,包括优先级管理和内核抢占;
仲裁者使用 Linux 的 cpuset 特性将内核分成管理的内核和未被管理的内核,未被管理的内核会分配给机器上的其他应用程序,而被管理的内存会分配给使用 Arachne 的进程。

图 2 - 拆分 CPU 资源
这种方案可以与现有的进程运行方式兼容,我们不需要修改内核,就可以直接利用 Linux 现有的特性管理 CPU 资源。
优先级管理
当应用程序启动时,它会调用 setRequestedCores: 方法通过 Socket 向仲裁者请求 CPU 资源,该方法的参数是一个数组,从左到右依次表示八种不同优先级的 CPU:
0 0 1 2 0 0 0 0
仲裁者使用了比较简单的优先级管理策略,高优先级的请求可以覆盖低优先级的请求,因为没有其他调度器的分时复用机制,并且调度基本都是协作式的,所以部分应用程序只要申请高优先级的资源就可以饿死其他进程,Arachne 中并没有解决这个问题,虽然它提出可以通过鉴权防止恶意资源申请,但是这仍然无法解决饥饿问题。
当应用程序想要向仲裁者申请 CPU 资源时,会经历如下所示的几个步骤:
- 应用程序在发出
setRequestedCores:后会即创建与请求核数相同的内核线程(Kernel Thread); - 调用
blockUntilCoreAvailable:阻塞这些线程等待仲裁者分配资源; - 当仲裁者决定为这些线程分配资源时,它会通过 cpuset 绑定线程和 CPU、通知并唤醒应用程序的内核线程,操作系统会负责将当前线程调度到绑定的 CPU 上;
- Arachne 运行时中的内核线程随后会在调度器中为其他的用户线程分配合适的资源;
每一个基于 Arachne 运行时的应用程序中都会启动对应数量的内核线程,运行时中的调度器会决定执行哪些用户态线程,该模型与 Go 语言的 G-M-P 模型也比较相似3,它们的初衷都是尽可能降低线程切换带来的额外开销,但是 Arachne 提供了对资源更细粒度的控制:

图 3 - Arachne 线程模型
需要注意的是仲裁者和应用程序之间的通信机制是不同的,应用程序会通过 Socket 访问仲裁者,而仲裁者发出的请求都是通过共享内存。这是因为应用程序在发出请求后可以陷入休眠等待响应或者资源的分配,但是 Socket 是相对比较昂贵的操作,所以仲裁者会通过共享内存请求应用程序。
Arachne 使用了协作的方式进行调度,当仲裁者需要回收资源时,应用程序可以延迟一段时间释放 CPU;如果应用程序超过 10ms 都没有释放资源,仲裁者就会通过 cpuset 将资源分配给其他程序,没有主动释放的程序会看到性能明显地下降。
Arachne 的运行时实现了老生常谈的用户态线程,但是这里的用户态线程针对特定的场景做出了优化,它主要支持细粒度的计算,其中包括大量生命周期极短的线程,例如常见的 HTTP/RPC 服务,它们会创建单独的线程处理外部的请求。
图 4 - HTTP 服务与线程
大多数的线程操作都需要在多个 CPU 之间通信,而跨核的通信会导致缓存缺失(Cahce Miss),缓存缺失大概需要 50 ~ 200 个 CPU 循环,这也是影响 Arachne 运行时性能的主要因素。为了解决缓存缺失带来的性能影响,运行时会在数据传输时并行执行其他的指令,优化 CPU 缓存以提升用户态线程的性能。线程的创建和调度是运行时的关键操作,优化这些操作的性能就可以降低延迟并提高吞吐量。
多数的用户态线程管理器都会在同一个 CPU 上创建线程并使用工作窃取(Work-stealing)4平衡多个 CPU 上的负载,但是工作窃取对于存在时间较短的线程来说是非常昂贵的,所以我们希望在线程创建时立刻触发负载均衡,将线程创建在其他的核心上;同时,为了减少程序中的缓存丢失,Arachne 将每一个线程的上下文都绑定了特定的 CPU 上,只有在仲裁者回收时才可能发生处理器迁移,大多数的线程在创建之后就不会触发迁移。当应用程序创建新的线程时:
- 运行时会在多个 CPU 中随机选择两个;
- 在上述两个 CPU 中选择活跃线程数较少的 CPU;
- 将线程开始的方法地址和参数拷贝到上下文中;
每个 CPU 上都有对应的 maskAndCount 变量,其中存储着正在执行的线程和当前 CPU 上的线程数。为了减少线程的缓存丢失,我们使用单独的缓存块(Cache Line)存储线程所有信息,这样创建线程最少只需要触发四次缓存丢失,分别是读取 maskAndCount、传输函数地址、参数和调度信息,能够最大限度的减少开销。
传统的调度模型会在运行时中引入准备队列(Ready Queue)保存可执行的线程,例如:Linux 和 Go 语言的调度器5,但是如果准备队列是跨 CPU 的,那么增加或者删除任务时都需要修改多个变量以及获取共享锁,这都会触发缓存丢失进而影响性能。

图 5 - 线程调度
为了减少程序中的缓存丢失,Arachne 的调度器不会使用准备队列,它会持续检查当前 CPU 上的所有活跃线程直到发现可以运行的线程,因为以下的两个原因,这个看起来非常简单的轮训机制实际上非常高效:
- 在同一时间,单个 CPU 上应该只会包含少数几个线程上下文;
- 当前线程一定会由其他核心唤醒,因为跨核的传输会带来缓存丢失,而在触发缓存丢失时可以并行扫描全部上下文不会带来过大的开销;
因为线程可能处于阻塞状态等待特定的执行条件满足,所以上下文中会包含 wakeupTime,即线程多久后需要被唤醒;线程可以通过 block(time) 和 signal(thread) 两个方法改变 wakeupTime 通知调度器当前线程的状态和唤醒时间。
为了能够让应用程序对 CPU 有更细粒度的控制,Arachne 不会在运行时中指定 CPU 的使用策略,如何使用 CPU 都是由独立的策略模块确定的,Arachne 中的一些默认核心策略如果不能满足应用程序的需求,它们还可以实现一些自定义的策略满足特定的需求。

图 6 - 线程类
与 Linux 调度器中的调度类比较相似,当应用程序创建新的用户线程时,它需要指定该线程的类,核心策略会根据调度类选择 CPU 执行。默认的核心策略中包含两个线程类,分别是独占的(Exclusive)和正常的(Normal),前者会为线程保留整个 CPU 资源,而后者会在多线程之间分享资源。
默认的核心策略中包含动态的 CPU 资源预估功能,它会使用以下的三个参数根据过去一段时间的负载和 CPU 使用情况调整当前应用程序申请的资源:
- 负载因子(Load Factor) — 当运行正常线程的所有 CPU 负载达到特定的阈值时,向仲裁者申请额外的 CPU;
- 时间间隔(Interval) — 用于预估占用资源的 CPU 采样区间,默认为过去的 50ms,这可以决定策略对负载变换的敏感程度;
- 滞后因子(hysteresis Factor) — 记录每次提升负载前的资源利用率,并根据该利用率减少申请的 CPU 资源;
作为 Arachne 中的默认策略,它提供的一定是相对简单的、普适的模型,我们可以根据自己的需求调整策略中的三个参数,也可以实现其他的策略。
论文的最后在线程的创建、控制权转移等常见的调度原语方面对比了 Arachne、std::thread、Go 和 uThreads 几种具有相似功能的线程管理器,Arachne 在几个方面都有不错的表现:
| Benchmark | Arachne | std::thread | Go | uThreads |
|---|---|---|---|---|
| Thread Creation | 217 ns | 13329 ns | 444 ns | 6132 ns |
| One-Way Yield | 93 ns | - | - | 79 ns |
| Null Yield | 12 ns | - | - | 6 ns |
| Condition Notify | 281 ns | 4962 ns | 483 ns | 4976 ns |
| Signal | 282 ns | - | - | - |
表 1 - 调度原语的开销对比
正如我们在文章中提到的,Arachne 与其他线程管理器使用了完全不同的设计思路,因为我们的目的是充分利用 CPU 资源,所以应用程序需要对资源有着更细粒度的掌握和控制,其他的线程管理器都会尽可能地屏蔽底层的实现细节,让上层只关注内部的一些逻辑,我们从软件工程的角度也不能说谁对谁错,但是在真正追求极致的性能时,一定清楚对下一层甚至下两层的信息,在线程调度器这个场景下就是 CPU 资源的详细使用情况。
Henry Qin, Qian Li, Jacqueline Speiser, Peter Kraft, and John Ousterhout. 2018. Arachne: core-aware thread management. In Proceedings of the 12th USENIX conference on Operating Systems Design and Implementation (OSDI’18). USENIX Association, USA, 145–160. ↩︎
Core aware thread management system https://github.com/PlatformLab/Arachne ↩︎
6.5 调度器 · Go 语言设计与实现 https://draveness.me/golang-goroutine/ ↩︎
Robert D. Blumofe and Charles E. Leiserson. 1999. Scheduling multithreaded computations by work stealing. J. ACM 46, 5 (Sept. 1999), 720–748. DOI:https://doi.org/10.1145/324133.324234 ↩︎

本作品采用知识共享署名 4.0 国际许可协议进行许可,转载时请注明原文链接,图片在使用时请保留全部内容,可适当缩放并在引用处附上图片所在的文章链接。你可以在 技术文章配图指南 中找到画图的方法和素材。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK