

微信上其实还有很多你不知道的事,Python微信平台开发编写实录
source link: http://developer.51cto.com/art/202005/616730.htm
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


本文主要讲述如何利用Python开发微信公众平台。
说明:如果你是Python小白,爬虫小白,觉得本节课程的代码晦涩难懂。没关系,不需要懂,按照步骤一步步操作就可以了。这一节我们主要是搭框架,几乎没有真正的爬虫代码。这些代码和操作,你可能一生也就只用这一次。下一节,我们再讲述怎么在这个框架上扩展我们的爬虫程序。
需要的操作:
- 微信公众账号的申请。
- 微信接口的获取,SAE的设置等。
- 简单的Python爬虫代码编写
需掌握的知识点:
- 了解微信公众号与云计算平台之间的连接关系。明确其运行机制。
- 了解web.py的概念,wsgi的机制。
- 了解简单的python爬虫知识,json解析,API调用,urllib库函数。
自动回复实现原理
首先了解一下,到底是什么样的机制能实现微信的自动回复功能呢?(不是微信系统的自动回复)原理就是微信平台将用户输入的文字发送到云平台上,然后云平台上运行的程序捕捉到这一文字信息,就return一个结果,然后云平台再将该结果返回至微信平台。最后微信平台将返回的结果展现给用户。用一张图表示一下:

微信开发者模式与SAE的设置
这一节我尽量讲的细致一些,如果仍有不清楚的,可以私信我。
首先需要两大平台支持:
- 微信公众平台;这个申请比较简单。只要有邮箱就可以免费申请个人版的订阅号。不再赘述。
- 云计算平台;我这里使用的SAE(新浪的去年本来就不收费,坑爹,今年开始收费了,单纯代码托管最低一天1毛),也可以用腾讯云。
具体步骤:
微信公众号的申请。
只要有邮箱就可以免费申请个人版的订阅号。不再赘述。
SAE的申请及设置
注册登录SAE之后,选用SAE

创建新项目,SAE暂时只支持Python2.7,Python3暂时用不了。


如果项目比较小,建议填写SVN,因为可以在线编辑。如果项目比较大,就Git吧。这里选用SVN。

创建第一个版本

可以开始编辑啦~

编写config.yaml和index.wsgi文件。
WSGI是PythonWeb服务器网关接口(Python Web Server Gateway Interface)。我们使用的是web.py框架。同类型比较强大的框架有Django,Flask等。为什么选用web.py呢,是因为它是轻量级的,而且有着良好的xml解析功能。插句题外话,web.py的开发者AaronH. Swartz是个十足的天才,可惜英年早逝。有个关于他的一部纪录片,推荐看一下:互联网之子。
好了,言归正传,我们首先编写config.yaml
name: pifuhandashu version: 1 libraries: - name: webpy version: "0.36" - name: lxml version: "2.3.4" ...
这里我们引入了web.py框架以及lxml模块,接着我们编写index.wsgi文件。
# coding: utf-8
import os
import sae
import web
from weixinInterface import WeixinInterface
urls = ('/weixin','WeixinInterface')
app_root = os.path.dirname(__file__)
templates_root = os.path.join(app_root, 'templates')
render = web.template.render(templates_root)
app = web.application(urls, globals()).wsgifunc()
application = sae.create_wsgi_app(app)
这里就是简单的python利用web.py网页开发的知识了。设置了根目录,模板目录,/weixin的路由,开启应用。
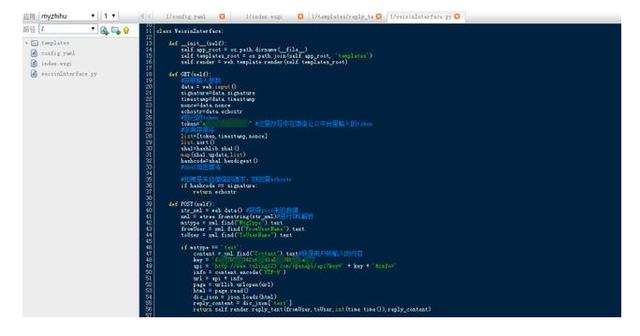
为了使页面显得更整洁,我们再新建了一个py文件weixinInterface.py(weixinInterface.py和index.wsgi在同一级目录,见后面的截图)。
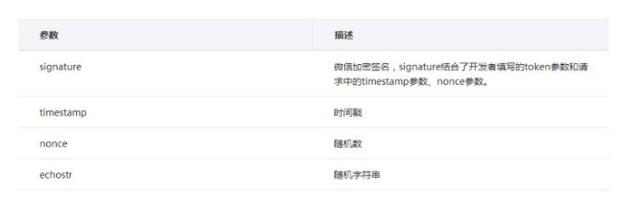
- 编辑weixinInterface.py,大小写一定要看清啊,不然很容易出错。注意自己填写一个专属的token,这个等会微信公众号设置里面有用到。
# -*- coding: utf-8 -*- import hashlib import web import lxml import time import os import urllib2,json from lxml import etree class WeixinInterface: def __init__(self): self.app_root = os.path.dirname(__file__) self.templates_root = os.path.join(self.app_root, 'templates') self.render = web.template.render(self.templates_root) def GET(self): #获取输入参数 data = web.input() signature = data.signature timestamp = data.timestamp nonce = data.nonce echostr = data.echostr #自己的token token = "XXXXXXXXXXX" #注意:填写之后在微信公众平台里输入的token!!! #字典序排序 list = [token, timestamp, nonce] list.sort() sha1 = hashlib.sha1() map(sha1.update,list) hashcode = sha1.hexdigest() #sha1加密算法 #如果是来自微信的请求,则回复echostr if hashcode == signature: return echostr
代码大致讲解一下,def __init__(self)是告诉我们模板文件的加载位置。 def GET(self)是应微信公众平台的要求,进行的token验证。这里的验证采用的是哈希算法。具体可参考微信官方的接口接入说明:微信公众平台接入指南。里面有个php示例。本文采用的是python实现。
微信开发者模式设置
基本设置

修改配置
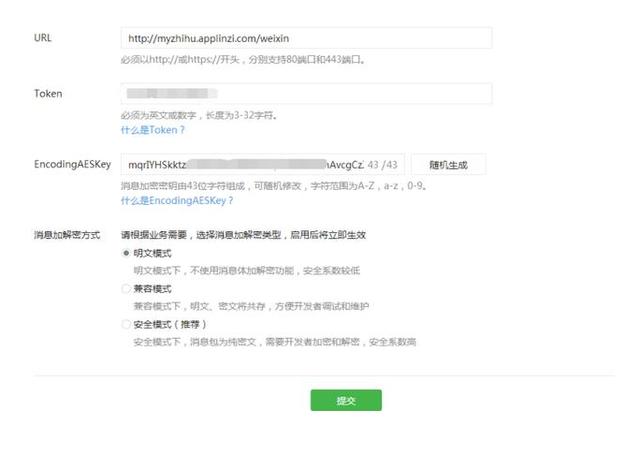
URL一定要认真填写,仔细核对。
比如查看url应用信息:


token填写刚才新浪SAE里面填写的token,一定要一致。EncodingAESKey可以随机生成。填完之后点击提交。如果提示“提交成功”。恭喜你,最关键的一步已经完成了。这个阶段可能要折腾蛮长时间。完成之后,一定要启用开发者模式!!!!切记!!!
微信机器人实现
上一步完成之后,我们就可以做一些有趣的事情:微信机器人。不过在此之前,还要完成一小步:模板的创建。由于微信开发是采用的xml的形式。为了先实现文本形式自动回复(后面可以实现回复音频,图文信息等形式),首先新建模板文件夹templates,然后在templates文件夹下创建reply_text.xml文件(文件放置位置见后面的截图)。根据微信消息被动回复所示,填入以下代码:
$def with (toUser,fromUser,createTime,content) <xml> <ToUserName><![CDATA[$toUser]]></ToUserName> <FromUserName><![CDATA[$fromUser]]></FromUserName> <CreateTime>$createTime</CreateTime> <MsgType><![CDATA[text]]></MsgType> <Content>$content</Content> </xml>
然后,在weixinInterface.py里的def GET(self)后面编写POST函数。该函数用来获取用户的ID,发送的消息类型,发送的时间等。判断用户发送的消息类型,如果是纯文本类型,if mstype == 'text',那么可以进行下一步操作。
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
mstype = xml.find("MsgType").text#消息类型
fromUser = xml.find("FromUserName").text
toUser = xml.find("ToUserName").text

为了实现微信机器人,我们需要实现自动回复的内容。这里有两种方式。
- 爬取网上的机器人回复的内容,比如找不到小黄鸡的接口,我就自己爬虫爬取它的回复结果。
- 调用自动能够回复的机器人API。
这里我选用第二种方法,采用的是图灵机器人的API。这种方法方便快捷,一般不会被墙。但是自由度不高,可拓展性差。
注册图灵机器人账号,注意是采用图灵的网页api,而不是授权。获取图灵机器人回复的key。几行代码就可以搞定微信机器人自动回复啦~
源码展示
index.wsgi源码
# coding: utf-8 import os import sae import web from weixinInterface import WeixinInterface urls = ( '/weixin','WeixinInterface', ) app_root = os.path.dirname(__file__) templates_root = os.path.join(app_root, 'templates') render = web.template.render(templates_root) app = web.application(urls, globals()).wsgifunc() application = sae.create_wsgi_app(app)
config.yaml源码
name: myzhihu version: 1 libraries: - name: webpy version: "0.36" - name: lxml version: "2.3.4" ...
templates下的reply_text.xml源码
$def with (toUser,fromUser,createTime,content) <xml> <ToUserName><![CDATA[$toUser]]></ToUserName> <FromUserName><![CDATA[$fromUser]]></FromUserName> <CreateTime>$createTime</CreateTime> <MsgType><![CDATA[text]]></MsgType> <Content>$content</Content> </xml>
weixinInterface.py源码
# -*- coding: utf-8 -*-
import hashlib
import web
import lxml
import time
import os
import json
import urllib
from lxml import etree
class WeixinInterface:
def __init__(self):
self.app_root = os.path.dirname(__file__)
self.templates_root = os.path.join(self.app_root, 'templates')
self.render = web.template.render(self.templates_root)
def GET(self):
#获取输入参数
data = web.input()
signature=data.signature
timestamp=data.timestamp
nonce=data.nonce
echostr=data.echostr
#自己的token
token="################" #这里填写在微信公众平台里输入的token
#字典序排序
list=[token,timestamp,nonce]
list.sort()
sha1=hashlib.sha1()
map(sha1.update,list)
hashcode=sha1.hexdigest()
#sha1加密算法
#如果是来自微信的请求,则回复echostr
if hashcode == signature:
return echostr
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
mstype = xml.find("MsgType").text
fromUser = xml.find("FromUserName").text
toUser = xml.find("ToUserName").text
if mstype == 'text':
content = xml.find("Content").text#获得用户所输入的内容
key = '#####################' ###图灵机器人的key
api = 'http://www.tuling123.com/openapi/api?key=' + key + '&info='
info = content.encode('UTF-8')
url = api + info
page = urllib.urlopen(url)
html = page.read()
dic_json = json.loads(html)
reply_content = dic_json['text']
return self.render.reply_text(fromUser,toUser,int(time.time()),reply_content)
尾记
本次教程实现了利用Python开发微信公众平台,能够自动回复用户输入的文字。包括了微信公众平台的设置,SAE的设置,相关代码的编写等。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK