

浅谈 CPU 分支预测技术 | Matt's Blog
source link: http://matt33.com/2020/04/16/cpu-branch-predictor/?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
最近在看 SQL 优化之 Code Generation 相关的内容,我们知道 Code Generation 是 SQL 优化的大杀器之一,不管是在 Apache Spark 还是 Apache Flink 中都有比较深入的应用(特别是在 Spark 中),Code Generation 最开始是在数据库中应用的,Spark 将其引入到 Spark SQL 的中优化,后来的 Flink 也借鉴了这一思想。Code Generation 是要解决什么问题呢?相信大部分人应该有所了解,简单来说就是减少虚函数调用、尽可能利用 CPU 分支预测的能力(会在 Code Generation 部分详细介绍,这里只需要了解这一背景即可),那么什么是 CPU 分支预测(Wikipedia: CPU Branch Predictor)呢?为什么虚函数调用会极大消耗 CPU 性能呢?这就是本文将要给大家介绍的内容。
CPU Instruction pipelining
在介绍 CPU 分支预测机制之前,先来看下 CPU 的流水线机制(Wikipedia: CPU Instruction pipelining)。
关于流水线(pipeline),这里举一个生活中的例子,比如在洗车时,当前面一辆车清洗完成进入擦洗阶段后,下一辆车就可以进入喷水阶段了,这就是一个典型的流水线场景(如下如所示),它不是说非要前面一辆车把清洗、擦洗全部完成后,下一辆车才能开始。
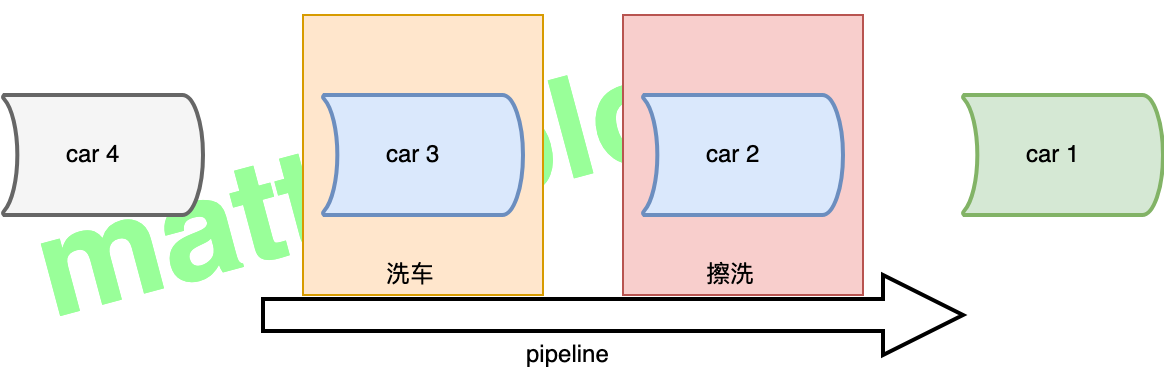
从这里也可以看出,流水线机制一个重要的特性就是 提高了系统的吞吐量,也就是单位时间内服务的总数,不过它会有一个轻微的延迟,对于上面的例子就是,一辆汽车在洗完之后需要开到擦洗的地方擦洗。在 CPU 的设计中,也有类似流水线化的机制,这个汽车就是指令,每个阶段完成执行执行的一部分。
CPU 中计算的流水线化
下面举一个示例,这里将系统执行分为三个阶段(A、B 和 C),如下图所示,每个阶段需要 100ps(picosecond,皮秒,也就是微微秒,即 $10^{-12}$),中间加载寄存器(也可以叫做流水线寄存器,pipeline register)需要 20ps。对于图 b,时间从左往右流动,对于指令 I1,三个方框分别代表三个阶段(图片来自 《深入理解计算机系统 第三版》 中插图)。
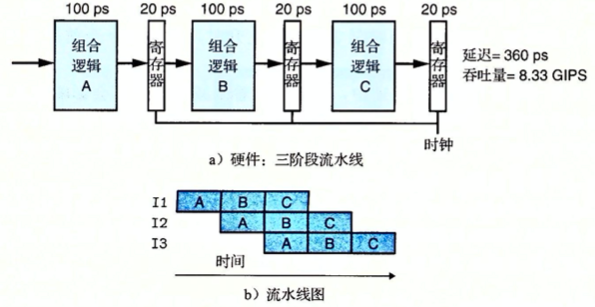
这样,每条指令都会按照三步经过这个系统,从头到尾需要三个完整的时钟周期,如上图所示,只要 I1 从 A 进入 B,就可以让 I2 进入 A 阶段了,以此类推。在稳定状态下,三个阶段都应该是活动的,每个时钟周期,一条指令离开系统,一条新的指令进入。在这个系统中,时钟周期设为 100+20=120ps,得到的吞吐量大约为 8.33GIPS,但是因为处理一条指令需要 3 个时钟周期,所以这条流水线的延迟就是 3*120=360ps,它相当于 一阶段 的系统,吞吐量提高了 2.67 倍,代价是增加了一些硬件以及延迟的增加(寄存器变多带来的延迟)。
流水线的局限
在上面的三阶段系统中,它是一个比较理想的情况,在这个系统中,我们可以将计算分成三个独立的阶段,每个阶段需要的时间是原来逻辑需要时间的三分之一,但是在实际生产中,会出现一些其他的因素,降低流水线的效率。
情况 1:阶段不一致的划分
在前面的例子划分的阶段中,每个阶段执行都是 100ps,但是实际中并不一定是这样的,假如 A 阶段是 50ps,B 阶段是 150ps,C 阶段是 100ps,在这种情况下,系统必须将时钟周期设置为 170ps(由最慢的来决定),这样的话,其吞吐量就变成了 5.88GIPS,由于时钟减慢,也导致了延迟增加到了 510ps。
因此,在 CPU 硬件设计时,将系统计算设计分为一组具有相同延迟的阶段将是一个严峻的挑战。
情况 2:流水线过深,收益反而下降
如果流水线过深,中间使用到的寄存器将会变多,寄存器使用带来的延迟在指令运行总延迟中的比重将会增大。一方面,在设计时,为了提高时钟频率,现代处理器会采用很深的流水线,另一方面,由于流水线过深,指令运行延迟会变长。所以,在实际设计时,电路设计师如何设计流水线寄存器,使其延迟尽可能减少,是高速微处理器面临重大挑战之一。
CPU Branch Predictor
在开始介绍 CPU 分支预测技术之前,可以先看下 StackOverflow 上一个非常有名的问题(现在有 3w+ 人认同第一个回答) —— Why is processing a sorted array faster than processing an unsorted array?,问题的大概是,对一个数组中的每个元素,先做判断,如果大于某个值,就做累加,就是这样一个简单的操作,发现一个有意思的现象,如果用 C++ 写这段代码,对于有序数组和无序数组分别做这个操作,性能大概相差五倍多,在 Java 中,差距小一点,大概是 1 倍。为什么会出现这个问题呢?
背后的原因就是 CPU 流水线下,CPU 采用分支预测技术,对于有序数组可以很好地 CPU 这一特性,而无序数组会使得分支预测手足无措。
什么是分支预测
在前面,我们了解到 CPU 为了提高吞吐量采用了流水线机制,比如下图中的 4 级流水线(图片来自 Wikipedia: CPU Instruction pipelining):
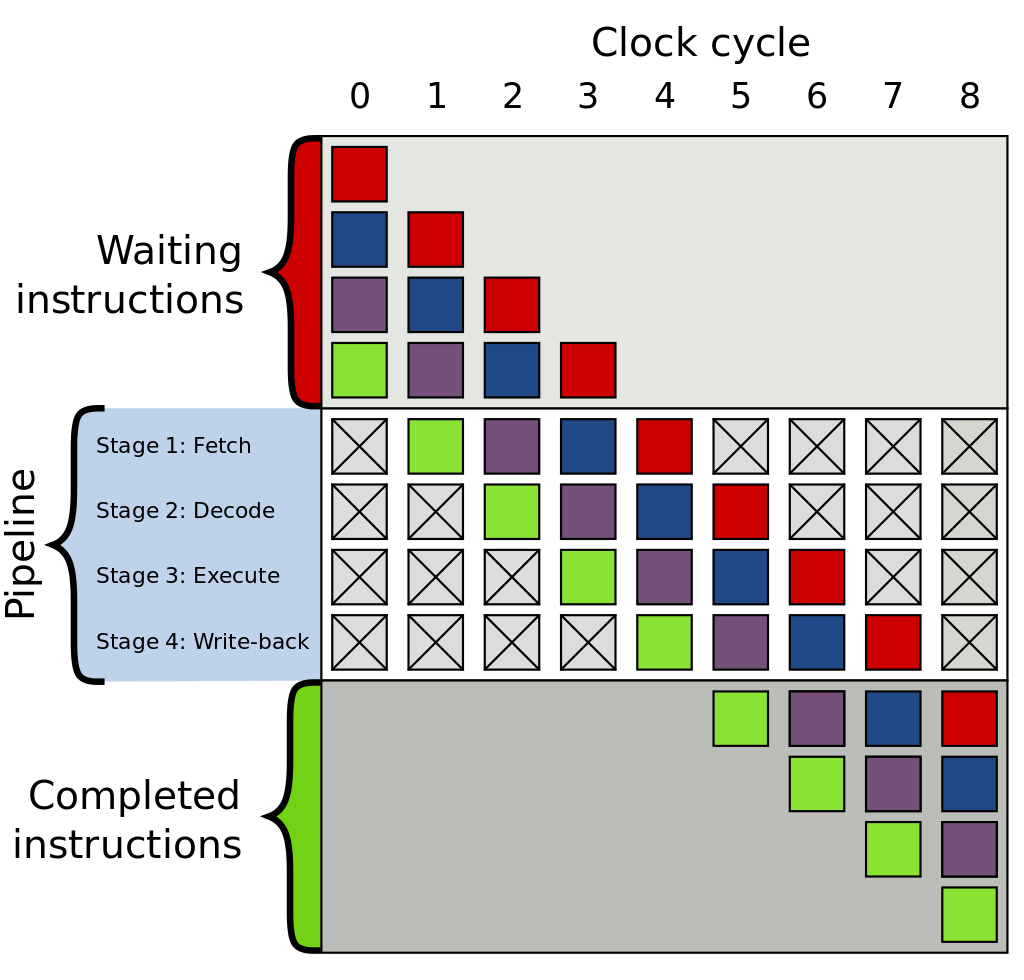
上图中的 CPU pipeline 有四个执行阶段:
- 读取指令(Fetch);
- 指令解码(Decode);
- 运行指令(Execute);
- 回写(Write-back)。
假设有三条指令,在上面这个四级流水线构架下(每个阶段都会花费一个时钟周期),pipeline 执行流程如下图所示:
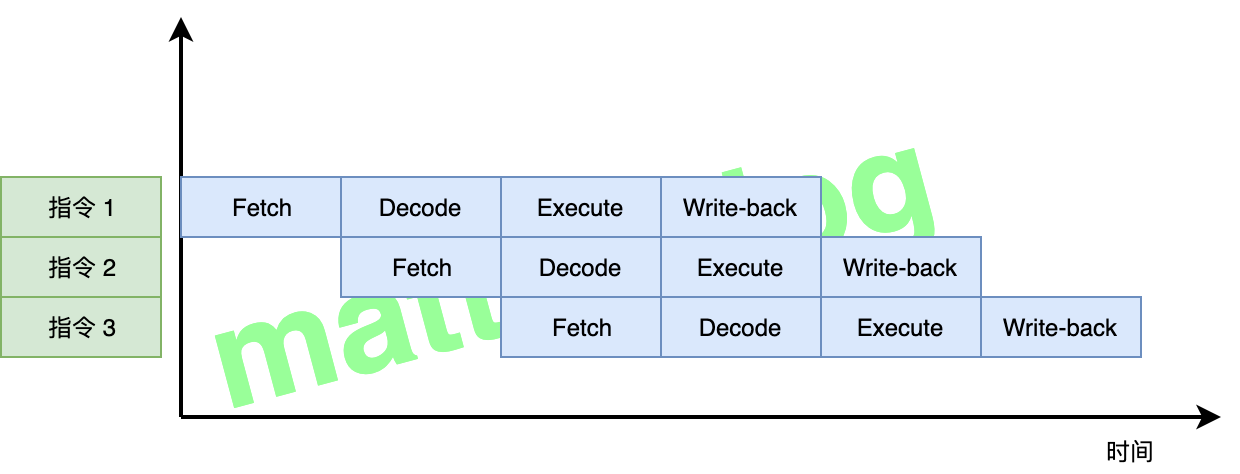
我们知道:如果没有流水线机制,一条指令大概会花费 4 个时钟周期,而如果采用流水线机制,当第一条指令完成Fetch后,第二条指令就可以进行Fetch了,极大提高了指令的执行效率。
上面是我们的期待的理想情况,而在现实环境中,如果遇到的指令是 条件跳转指令,只要当前面的指令运行到执行阶段,才能知道要选择的分支,显然这种 停顿 对于 CPU 的 pipeline 机制是非常不友好的。而 分支预测技术 正是为了解决上述问题而诞生的,CPU 会根据分支预测的结果,选择下一条指令进入流水线。待跳转指令执行完成,如果预测正确,则流水线继续执行,不会受到跳转指令的影响。如果分支预测失败,那么便需要清空流水线,重新加载正确的分支(实际上目前市面上所有处理器都采用了类似的技术)。
分支预测技术
这里看下常见的分支预测技术,主要有:静态分支预测、动态分支预测 和 协同分支预测 三种,有兴趣的可以看下下面的几篇文章:
关于这三种技术,这里就不再展开了,简单总结一下。
- 静态分支预测:实现起来很简单、成本低,而且在生产中,这种预测正确率的波动范围很大;
- 动态分支预测:根据指令的不同及历史信息(存储在一张分支历史表中 —— Branch History Table)作出相应的预测,常见的有 1-bit/n-bit 动态预测;
- 协同分支预测:利用代码中分支跳转指令之间的关联关系,提高分支预测的准确率。
Java 中的虚函数调用
Java 本身没有虚函数的概念,它在 C++ 中是最常见的。在 C++ 中,虚函数通过 virtual 关键字定义,实现在类的继承当中,编译器通过判断对象的类型,在调用函数时,执行对应的函数。Java 中并没有显式去定义虚函数的概念,Java 中实际上每个函数都默认是一个虚函数(声明 final 关键字的函数除外),比如下面示例中 eat() 方法。
1 | public class Animal { |
虚函数存在的意义就是为了实现多态,Java 通过 动态绑定,不仅实现了虚函数的功能,也使得代码逻辑更为简洁。
到这里,相信大家已经对 CPU 的流水线机制及 CPU 的分支预测技术有了一定的了解。回到 code
上,如果代码里充满着各种不可预知的条件跳转指令,将会极大影响 CPU 的执行效率,数据库中采用的 Volcano-style execution engine(火山执行引擎)在代码中充满着各种虚函数调用(详细机制在后面内容中再介绍),在编译器中,虚函数需要调用查找虚函数表,并且虚函数调用是一个非直接跳转逻辑,在这个逻辑中,最大的代价是可能导致错误的 CPU 分支预测,一次错误的分支预测会导致需要 10 几个周期的系统开销。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK