

Wootric moved ML deployment pipeline from AWS to GCP
source link: https://engineering.wootric.com/move-from-aws-to-gcp-ml-deployment-pipeline/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

by Prabhat Jha and Ryan Smith
We have written quite extensively about our machine learning journey for Wootric's text analytics product, CXInsight. However, those write-ups have been mostly about building ML models and how we evolved from simpleBag of Words approach to the state of the art transfer learning usingBERT.
Our ML deployment pipeline has similar evolution but, instead of being incremental, it’s a jump from a monolith to the world of microservices. We went from a hand-stitched tightly-coupled deployment on AWS to microservices like deployment on the Google Cloud AI Platform.
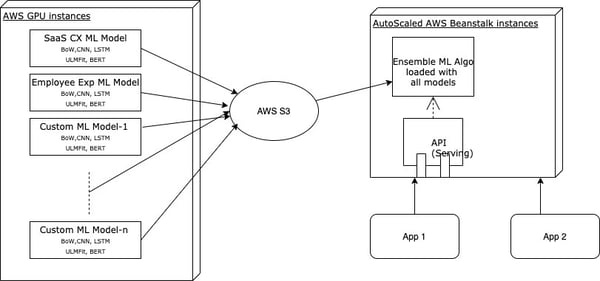
CXInsight v0 ML architecture on AWS
A high-level deployment flow on this architecture includes the following:
-
Build different ML models on AWS GPU servers
-
Upload models to S3 with a predefined naming convention for versioning
-
Flask app running on Beanstalk downloads and loads all the models into memory
-
Flask app gets predictions from each model and combines them using our proprietary ensemble algorithm
Advantages of v0 ML architecture on AWS:
-
Most of the well-known advantages of a monolith apply here:
-
Simple to develop
-
Simple to test
-
Simple to deploy
-
Simple to debug
-
Channel our collective engineering experience
-
-
We could build UX and API without getting bogged down in ML plumbing
-
Helped us quickly iterate and get feedback from our early adopters
Shortcomings of v0 ML architecture on AWS:
-
This is very bulky, as we have every model downloaded and loaded into memory on each instance. Start-up times for each instance were insanely long and got longer as we added more models and each model got bigger as we got more labeled data.
-
Caused errors when trying to autoscale during times of peak load.
-
Autoscaling was inherently limited by how effective it could be since the delay between instances was significant. Additionally, each instance we autoscale with had to be large enough to contain all of our models in memory - this incurred a much higher price per instance than necessary.
And, since startup time was so long, we had to keep a minimum of 1 big instance up at all times - even when there were no requests coming in. As you can imagine, this was quite expensive.
-
Models are coupled with the app code - deploying a new version of the Flask app necessitates redeploying the models and vice versa.
-
As we added more and more models, we continued having to increase the size of our instance. This is not scalable in several dimensions as we start adding custom models for customers more and more frequently now.
-
We would often get into some weird state where the fix was to rebuild the Beanstalk environment instead of a restart. This significantly increased our MTTR .
CXInsight v1 ML architecture on GCP AI Platform
A high-level deployment flow on this architecture includes the following:
-
Build different models on GPU servers.
-
Upload and deploy these models for prediction using the AI Platform
-
Runs the lightweight Flask app on GCP Cloud Run.
-
Flask makes batch prediction calls to each necessary model for the current request.
-
It combines these outputs with our proprietary ensemble method and returns the result in the response.
-
.jpg?width=900&name=Wootric%20CXInsighr%20ML%20System%20Architecture%20on%20Google%20Cloud%20Platform%20(GCP).jpg)
Advantages of new v1 architecture on GCP AI Platform:
-
The models and their serving layers have auto-scaling enabled, so only the exact models we need for sets of requests are being spun up.
-
The Flask app is now lightweight and can autoscale effectively. This eliminates most errors and excessive load times we were seeing with our bulky v0 architecture.
-
Models and App code are separate! This means we can deploy updates to the models without updating the application version, and vice versa.
-
Versioning is handled automatically with AI Platform, so we no longer need to handle everything (still have to deal with saving appropriate files) to do with versioning in our deploy scripts.
-
This approach now scales perfectly as we continue to add custom models for customers. The new models are only called when we are processing that customer’s data, so they don’t have any latency or memory effects on all other requests.
Shortcomings of new v1 architecture on GCP AI Platform:
-
Unfortunately, the latency per response has gone slightly up for smaller batches of requests. This is because we are now relying on a web request to access the model when this was previously done locally on the instance. Interestingly, as batch sizes increase, the latency difference is mostly negligible.
-
We cannot have a minimum instance count on Google Cloud Run (although they’ve noted that they plan to implement this feature soon). Occasionally instance count goes to zero. This is nice for our wallet but causes a small delay when clusters of requests start streaming in. In practice, it’s not very noticeable, but it would be nice to eliminate.
This blog should not be seen as a ding on AWS. Our v0 architecture on AWS served our needs for more than a year and helped us onboard the first set of customers as we highlighted above in the advantages of our v0 architecture. When we started, our needs were limited, AWS SageMaker did not exist and neither did GCP AI Platform. We wanted to build something quickly to show value to our customers instead of spending engineering resources on building a fancy ML pipeline.
When we started thinking about the next steps in our ML journey, GCP AI Platform’s approach seemed intuitive and felt right for the problem we had. This has now been validated by its flexibility and scalability.
Microservices have advantages but they come with their own baggage, so we only wanted to deal with the complexities when there was a need. We at Wootric generally let business drive the technology adoption instead of adopting hip technology just for the sake of it. So far we have been happy with the flexibility we now have and feel confident that this new architecture will scale with the growth we anticipate.
You can read about the problems this platform solves on the CXInsight product page . What would your architecture look like? What would your next iteration look like atop our v1 architecture? Tweet us at Wootric.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK