

浏览器解析机制与渲染过程
source link: https://p2hm1n.com/2020/03/10/浏览器解析机制与渲染过程/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

论一张图打败你学 XSS 的信心。(转自微博

附上 MDN DOM 事件参考: https://developer.mozilla.org/zh-CN/docs/Web/Events
本文参考多篇文章,涉及相关晦涩难懂名词解释,术语解释。均是 CTRL c v 。属于只可意会不可言传的领域。其他的知识都会尽量经我口中阐述的简单一点。
浏览器的解码
浏览器的解码规则
- HTML解析器对HTML文档进行解析完成HTML解码并且创建DOM树
- javascript 或者 CSS解析器对内联脚本进行解析,完成JS CSS解码
- URL解码会根据URL所在的顺序不同而在JS解码前或者解码后
当浏览器从网络堆栈中获得一段内容后,触发HTML解析器来对这篇文档进行词法解析。在这一步中字符引用被解码。在词法解析完成后,DOM树就被创建好了,JavaScript解析器会介入来对内联脚本进行解析。在这一步中Unicode转义序列和Hex转义序列被解码。同时,如果浏览器遇到需要URL的上下文,URL解析器也会介入来解码URL内容。在这一步中URL解码操作被完成。由于URL位置不同,URL解析器可能会在JavaScript解析器之前或之后进行解析。
Example A: <a href="UserInput"></a>
Example B: <a href=# onclick="window.open('UserInput')"></a>
Example C: <a href="javascript:window.open('UserInput')">
在例A中,HTML解析器将首先开始工作,并对UserInput中的字符引用进行解码。然后URL解析器开始对href值进行URL解码。最后,如果URL资源类型是JavaScript,那么JavaScript解析器会进行Unicode转义序列和Hex转义序列的解码。再之后,解码的脚本会被执行。因此,这里涉及三轮解码,顺序是HTML,URL和JavaScript。
在例B中,HTML解析器首先工作。然而接下来,JavaScript解析器开始解析在onclick事件处理器中的值。这是因为在onclick事件处理器中是script的上下文。当这段JavaScript被解析并被执行的时候,它执行的是“window.open()”操作,其中的参数是URL的上下文。在此时,URL解析器开始对UserInput进行URL解码并把结果回传给JavaScript引擎。因此这里一共涉及三轮解码,顺序是HTML,JavaScript和URL。
例C与例A很像,但不同的是在UserInput前多了window.open()操作。因此,对UserInput多了一次额外的URL解码操作。总的来说,四轮解码操作被完成,顺序是HTML,URL,JavaScript和URL。
HTML 解析
概括 HTML 中五类元素。详细可直接参考HTML5 语法
https://www.w3.org/html/ig/zh/wiki/HTML5/syntax-
空元素: 空一字体现在不能容纳内容。一般的标签由
<start>content</end>这样组成。空元素意味着没有闭合标签的标签。如:<area>,<br>,<base> -
原始文本元素: 可以容纳内容。
<script>和<style>。 -
RCDATA元素,可以容纳文本和字符引用。
<textarea>和<title> - 外部元素,可以容纳文本、字符引用、CDATA段、其他元素和注释: 如 MathML命名空间或者SVG命名空间的元素
- 基本元素,可以容纳文本、字符引用、其他元素和注释: 除了以上4种元素以外的元素
上面的内容我提炼了较为陌生的专业术语
- 字符引用
- RCDATA
- 外部元素
什么是字符引用?
字符引用包括“字符值引用”和“字符实体引用”。如在HTML中, <
对应的字符值引用为 <
,对应的字符实体引用为 <
。字符实体引用也被叫做“实体引用”或“实体”
——》再次延伸概念: 字符实体
字符实体是一个转义序列,它定义了一般无法在文本内容中输入的单个字符或符号。一个字符实体以一个 &
符号开始,后面跟着一个预定义的实体的名称,或是一个 #
符号以及字符的十进制数字。
——》产生问题: 为啥我要用字符实体呢,要经过转义这么麻烦的操作 ——〉HTML字符实体
在HTML中,某些字符是预留的。例如在HTML中不能使用“<”或“>”,这是因为浏览器可能误认为它们是标签的开始或结束。如果希望正确地显示预留字符,就需要在HTML中使用对应的字符实体。
外部元素容纳种类的比空元素、原始文本元素多,有什么用呢?
Foreign elements ——》 SVG黑魔法
<svg><script>alert(1)</script>
这个payload能执行的原因是因为 <svg>
遵循XML和SVG的定义。在XML中, (
会被解析成 (
。同理 <svg><script>alert(1);</script>
也可以造成 XSS
tips: 在XML中实体会自动转义,除了 <![CDATA[
和 ]]>
包含的实体
下面开始进入HTML解析过程…
一个HTML解析器作为一个状态机,HTML解析器有很多种状态。进行状态转换的方式是从输入流中获取字符并按照转换规则转换。以 <start>content</end>
为例子。HTML识别开始和结束标签的核心是 /
符号。当HTML解析器遇到 <
且没有 /
。就会进入 标签开始状态
然后转变到 标签名状态
, 前属性名状态
… 最后进入 数据状态
。 并释放当前标签的token。当解析器处于 数据状态
时,它会继续解析,每当发现一个完整的标签,就会释放出一个token。
容纳字符实体的作用: 在这些状态中HTML字符实体将会从 &#...
形式解码。三种情况可以容纳字符实体: 数据状态中的字符引用
, RCDATA状态中的字符引用
和 属性值状态中的字符引用
。
有一种可以容纳字符引用的情况是 RCDATA状态中的字符引用
。这意味着在 <textarea>
和 <title>
标签中的字符引用会被HTML解析器解码。且在解析这些字符引用的过程中不会进入 标签开始状态
。对RCDATA有个特殊的情况。在浏览器解析RCDATA元素的过程中,解析器会进入 RCDATA状态
。在这个状态中,如果遇到 <
字符,它会转换到RCDATA小于号状态。如果<字符后没有紧跟着/和对应的标签名,解析器会转换回RCDATA状态。这意味着在RCDATA元素标签的内容中(例如 <textarea>
或 <title>
的内容中),唯一能够被解析器认做是标签的就是 </textarea>
或者 </title>
。当然,这要看开始标签是哪一个。因此,在 <textarea>
和 <title>
的内容中不会创建标签,不会有脚本执行。
URL 解析
URL资源类型必须是ASCII字母 (U+0041-U+005A || U+0061-U+007A)
,不然就会进入“无类型”状态。例如,你不能对协议类型进行任何的编码操作,不然URL解析器会认为它无类型。
JavaScript 解析
Unicode转义序列只有在标识符名称里不被当作字符串,也只有在标识符名称里的编码字符能够被正常的解析。javascript解码器无法试别编码后的控制字符,比如:单引号,双引号和圆括号,之后会用一些例子进行详细说明。
Python 转码脚本
自己最近在写一个XSS的扫描脚本,其中一个模块具有判断 XSS payload 的有效性的功能。这里给出部分转码片段
import html
import re
from urllib.parse import unquote
payload = ''
def decodeHTML():
dh = html.unescape()
return dh
def decodeURL():
du = unquote()
return du
def decodeUnicode(payload):
duni = payload.encode('utf-8').decode('unicode_escape')
return duni
从payload看解析流程
1、 <a href="%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29"></a>
不弹窗, 原因: 识别到 href ,属性值状态中的字符引用。进入url模块解析。URL规定协议,用户名,密码都必须是ASCII。且不能对协议类型进行任何的编码操作。这里的 javascript
协议无法识别。
2、 <a href="javascript:%61%6c%65%72%74%28%32%29">
弹窗, 原因: 属性值状态中的字符引用。识别到实体化编码内容,进入html解码得到 <a href="javascript:%61%6c%65%72%74%28%32%29">
。然后进入 URL 解析。此时可正确识别协议类型。解码得到 <a href="javascript:alert(2)">
最后 JavaScript 解析。
3、 <a href="javascript%3aalert(3)"></a>
不弹窗, 原因同一, 这里 javascript:
为协议,任何一部分内容都不能编码
4、 <div><img src=x onerror=alert(4)></div>
不弹窗, 原因: 属性值状态中的字符引用,先进行 HTML 解析。但 HTML 解析机制中 <
会被 HTML 解码,但不会进入标签开始状态,当然也就不会创建 img 元素。(HTML编码就是为了显示这些特殊字符,而不干扰正常的DOM解析)
5、 <textarea><script>alert(5)</script></textarea>
不弹窗, 原因为: <textarea>
是RCDATA元素,可以容纳文本和字符引用,注意不能容纳其他元素,HTML解码得到 <textarea><script>alert(5)</script></textarea>
但 <textarea>
只容纳文本和字符引用。因此js无法执行
6、 <textarea><script>alert(6)</script></textarea>
不弹窗, 原因同5
7、 <button onclick="confirm('7');">Button</button>
弹窗, 原因: 属性值状态中的字符引用,先进行HTML解码。然后JS执行
8、 <button onclick="confirm('8\u0027);">Button</button>
不弹窗, 原因: 在JavaScript中,标识符只能包含字母或数字或下划线(“ _
”)或美元符号(“ $
”),且不能以数字开头。 onclick
中的值会交给JS处理,在JS中只有字符串和标识符能用Unicode表示, '
显然不行,JS执行失败。
9、 <script>alert(9);</script>
不弹窗, 原因: script
标签属于原始文本元素。无法容纳字符引用,所以无法进行HTML解码。因此JS解析时并不能执行弹窗
10、 <script>\u0061\u006c\u0065\u0072\u0074(10);</script>
弹窗, 原因: 直接进入 JavaScript 解析。且发现unicode编码,其为 alert 标识符进行编码后的字符串。所以能先解码,然后执行
11、 <script>\u0061\u006c\u0065\u0072\u0074\u0028\u0031\u0031\u0029</script>
不弹窗, 原因同8: 出现括号进行了unicode编码,JS无法识别编码后的控制字符
12、 <script>\u0061\u006c\u0065\u0072\u0074(\u0031\u0032)</script>
不弹窗, 其实个人最开始看到payload是感觉能弹窗的,后来参考了别人的思路。发现 \u0031\u0032
在解码的时候会被解码为字符串12。需要引号包裹。因此不执行JS
13、 <script>alert('13\u0027)</script>
不弹窗,原因同8: 出现单引号进行了unicode编码,JS无法识别编码后的控制字符
14、 <script>alert('14\u000a')</script>
弹窗。原因: \u000a
在JavaScript里是换行,就是 \n
,直接执行
组合拳:
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)"></a>
先进行HTML解码得
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)"></a>
然后进入 URL 模块处理,发现完整 javascript:
协议,进行URL解码。得 javascript:\u0061\u006c\u0065\u0072\u0074(15)
控制字符 ()
未被unicode编码,因此进行 JavaScript 解码,成功弹窗
浏览器渲染
浏览器的呈现引擎
呈现引擎默认可以解析html文档、xml文档以及图片等资源并将解析后的内容展示给用户。通过各种插件(浏览器扩展程序)浏览器还可以展示其他各类型的web资源,如pdf插件可以让浏览器展示pdf文档。不同浏览器使用的呈现引擎也不一样,目前主流的呈现引擎有Webkit、Blink(Webkit的一个分支)、Gecko、Trident、EdgeHTML(Trident的一个分支)。
浏览器 呈现引擎 Chrome Blink(Chrome 28+)Webkit(Chrome 27-) Safari Webkit Firefox Gecko Edge EdgeHTML IE Trident
页面呈现原理
当我们点击一个链接,服务器将 HTML 代码传输到我们的浏览器,浏览器在接收到这份 HTML 代码之后进行的页面的呈现,粗略的说会经过以下这些步骤:
- DOM 树的构建(Parse HTML)
- 构建 CSSOM 树(Recaculate Style)
- 合并 DOM 树与 CSSOM 树为 Render 树
- 布局(Layout)
- 绘制(Paint)
- 复合图层化(Composite)
页面呈现过程中的阻塞
- 当遇到 JavaScript 脚本或者外部 JavaScript 代码时,浏览器便停止 DOM 的构建(阻塞 1)
-
当遇到
<script>标签需要执行脚本代码时,浏览器会检查是否这个<script>标签以上的 CSS 文件是否已经加载并用于构建了 CSSOM,如果<script>上部还有 CSS 样式没加载,则浏览器会等待<script>上方样式的加载完成才会执行该<script>内的脚本(阻塞 2) - DOM 树与 CSSOM 树的成功构建是后面步骤的根基(同步阻塞)
- 同时外部脚本、外部样式表的下载也是耗费时间较多的点
Webkit和Gecko的流程对比
Webkit的主要流程(图片摘自Tali Garsiel的研究成果)
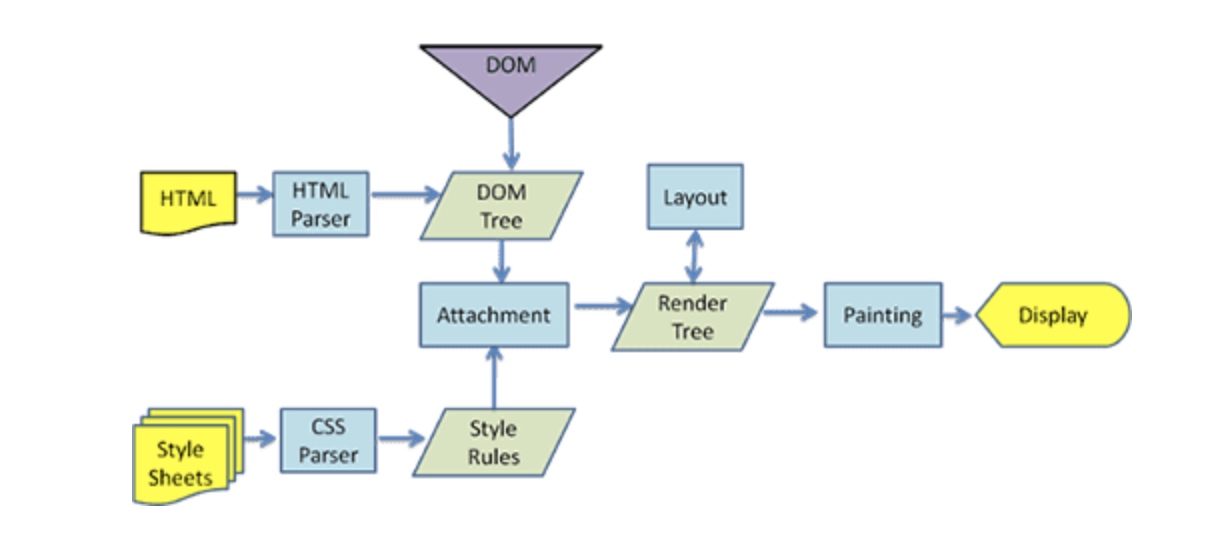
Gecko的主要流程(图片摘自Tali Garsiel的研究成果)
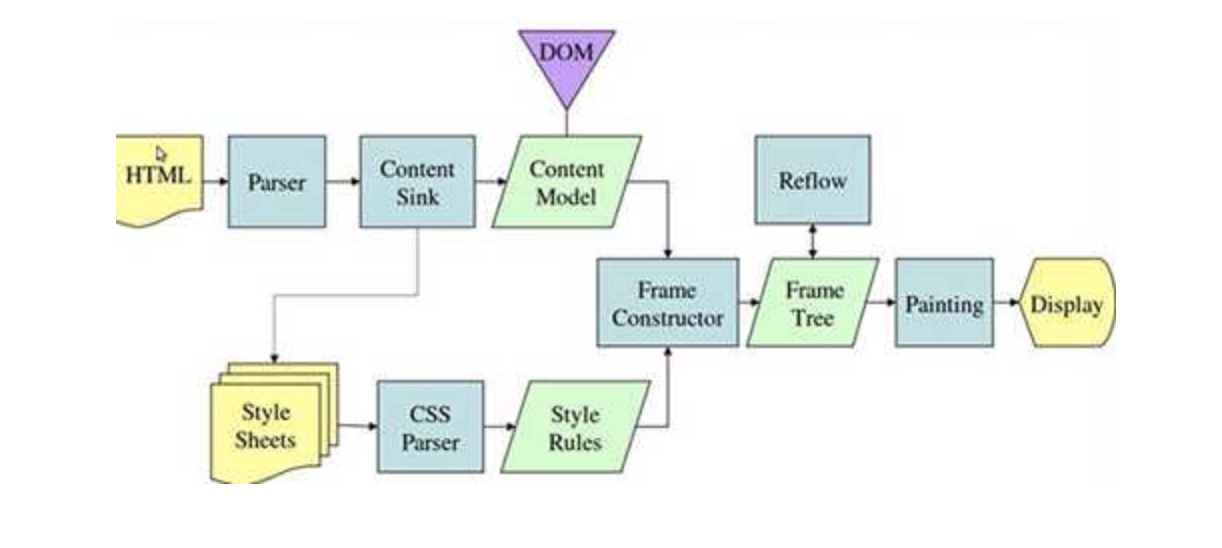
参考链接
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK