

流控技术演进
source link: https://www.sdnlab.com/23763.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

作者简介:盛科网络 王俊杰
1.流控技术概要
1.1.流控技术与RDMA
随着数据中心网络技术和带宽不断发展,流控技术在网络中发挥着越来越重要的作用,但一直未曾有过很大变革。直到无损网络的出现,流控技术出现新突破。作为以太网的基本功能之一,流控技术用于可以防止拥塞的情况下出现丢包,还能配合发送端合理的调整发送速率,从整体上保障网络带宽的最高效率。
对于降低网络时延的追求是永无止境,如何突破网络时延瓶颈所在,就先从RDMA技术说起。
1.2.RDMA工作原理
RDMA(Remote Direct Memory Access)技术是一种直接在内存和内存之间进行数据互传的技术,在数据传输的过程中完全实现了Kernel Bypass,CPU不需要参与操作,这也是RDMA在降低CPU消耗的同时,还能带来低时延的原因。
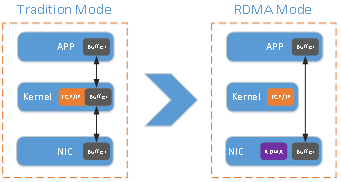
如上图所示,对比传统的网络传输机制,RDMA无需操作系统和TCP/IP协议栈的介入。RDMA的内核旁路机制,允许应用与网卡之间的直接数据读写,将服务器内的数据传输时延降低到1us以下。同时,RDMA的内存零拷贝机制,允许接收端直接从发送端的内存读取数据,极大的减少了CPU的负担,提升CPU的效率。
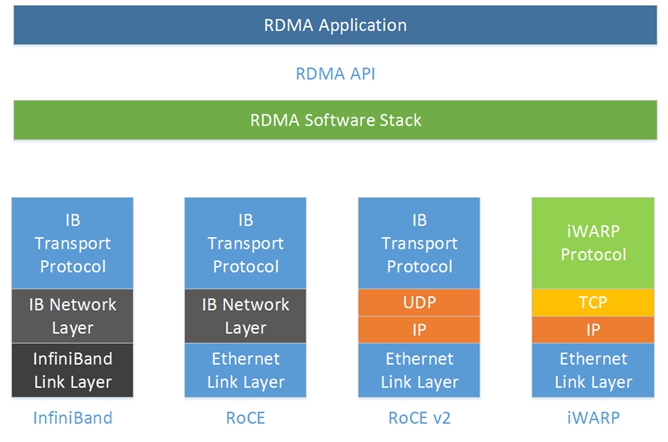
RDMA从Infiniband承载协议演进到以太网TCP/UDP承载协议,中间,网卡侧分别有厂商支持RoCEv2,iWARP,甚至Raw TCP。在近两年发布的智能网卡,包括Mellanox,Intel等厂商,基本都能满足不同场景对RDMA的需求。
基于TCP的RDMA,本质上是将“无损”寄托在TCP的可靠性上,而基于RoCEv2的无损网络则是将“无损”放在了流控机制。本文所提及的流控技术,主要是指基于RoCEv2的流控技术。
1.3.RDMA网络的关键技术
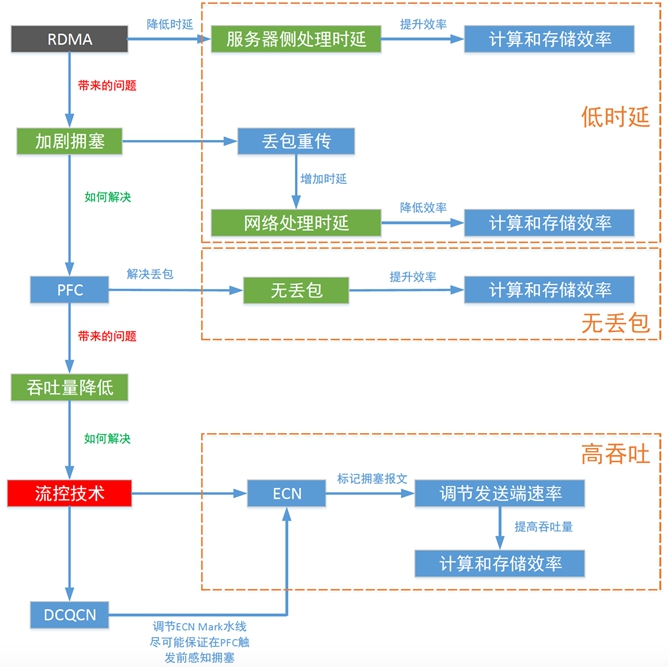
如上图所示,如果以太网需要实现无损,必须要优化这三个指标,具体实现原理如下:
- RDMA技术降低了服务器侧的处理时延,提升了计算和存储的效率,也减少了CPU资源的消耗。但是,带来了新的问题,加剧了网络的拥塞。
- 拥塞会带来两个严重的影响,一是拥塞使得网络处理时延增大,二是会导致业务丢包,业务因为丢包重传又增加了时延,拥塞问题会严重影响计算和存储效率。
- 通过PFC解决拥塞场景下的丢包和重传时延,提高计算和存储的效率。如果网络中出现大量PFC Pause,不但会降低吞吐量,还有可能诱发PFC Dead-lock。
- 总结来说,RDMA网络实现“低时延”,“无丢包”,“高吞吐”的关键是流控技术。
2.流控技术原理
2.1.PFC

上图中Pause 帧的各字段定义和描述如下:
- MACDA:目的MAC 地址,长度为6 字节,该组播地址是01:80:C2:00:00:01;
- MACSA:源MAC 地址,长度6 字节,为发送该Pause 帧的设备MAC 地址;
- Ether Type:以太网类型,长度为2 字节,Pause 帧的类型为0x8808;
- Control opcode:MAC 控制操作码,长度为2 字节,PFC 的Pause 帧也是MAC 控制的一种,对应的操作码是0x0101;
- Class-Enable vector:反压使能向量,长度2 字节,E[0~7]对应反压的不同优先级;
- Time:反压定时器,长度16 字节。当为0 时,表示取消反压,恢复对端报文发送;

当设备的出口转发发生拥塞,导致接收报文的入端口Buffer 占用超过PFC 水线,会触
发Pause 帧进行反压上游设备停止发包,具体机制描述如下:
- 交换机SW2 的端口2 在转发数据流时出现拥塞,导致数据流在入口1 的Buffer 占用超过PFC 水线触发Pause 帧反压SW1 的端口2,以停止Priority 为3 的数据流发向SW2;
- 收到Pause 帧的上游设备SW1 会暂停该优先级的数据流发送,同时SW1 的入端口1 还在接收数据流,导致SW1 的入端口1 的Buffer 占用增加。因此,SW1 的入端口1 的Buffer 占用依赖SW2 的入端口1 的Buffer 占用;
- 如果上游设备SW1 的入端口1 的Buffer 也超过PFC 水线,会触发Pause 帧继续向上游反压;
- 最终,从源头上降低该优先级数据流的速率,防止拥塞场景下出现丢包;
PFC 的水线分为XON 水线和XOFF 水线,具体作用说明如下:
- XON:使能发送的Pause 帧,代表对方可以发送数据了。
- XOFF:使能发送的Pause 帧,代表对方停止发送数据。
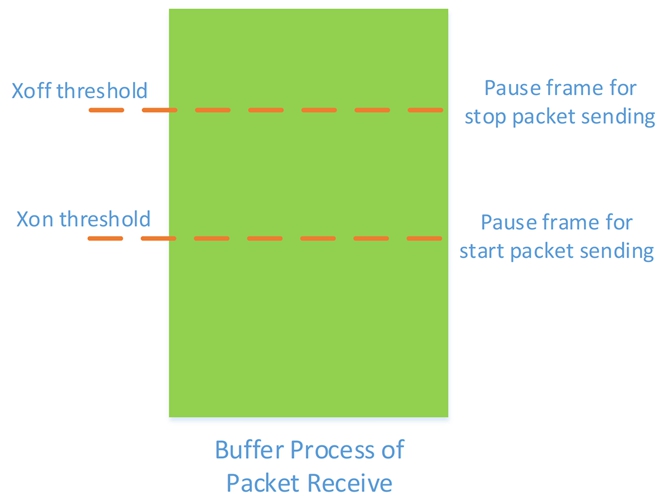
如上图所示,报文的入端口的Buffer 用于报文缓存,在使能PFC 时,需要设置触发Pause帧的水线,也就是超过Xoff Threshold 水线会触发停止对端发包的Pause 帧,低于Xon Threshold 水线会触发恢复对端发送的Pause帧。
PFC水线是基于入端口Buffer 进行触发的,入端口方向提供的8 个队列可以将不同优先级的业务报文映射到不同队列上,从而实现不同优先级的报文分配不同的Buffer。

如上图所示,具体到每个队列,其Buffer 分配根据使用场景分为三个部分:保存缓存,
共享缓存,Headroom。
- 保证缓存:每个队列的专用缓存,确保每个队列均有一定缓存以保证基本转发;
- 共享缓存:流量突发时可以申请使用的缓存,所有队列共享;
- Headroom:在触发PFC 水线后,到服务器相应降速前,还可以继续使用的缓存;
2.2.ECN

如上图所示,IP 报文头部中的DSCP 字段有2 Bit 用于标识ECN。这2 个Bit 分别是:
ECT(ECN Capable Transport)和CE(Congestion Experienced)。
- 当ECT 为0,CE 为0 时,表示IP 报文不支持ECN;
- 当ECT 为0,CE 为1 时,表示IP 报文支持ECN;
- 当ECT 为1,CE 为0 时,表示IP 报文支持ECN;
- 当ECT 为1,CE 为1 时,表示IP 报文支持ECN 且发生拥塞;
ECN 是报文在网络设备出口发生拥塞时,将使能ECN(当IP 报文的ECN 字段为01 或10,表示使能ECN)的IP 报文头部的ECN 字段标记ECN=11,表示该IP 报文遇到网络拥塞,且该IP 报文不会被WRED 机制丢弃。如果接收服务器发现IP 报文的ECN 字段被标记成11,就立刻产生CNP 拥塞通知报文,并将该报文发送带源服务器,CNP 消息里包含了拥塞的数据流信息,远端服务器接收到后,通过降低相应的数据流发送速率,环节网络设备拥塞,从而避免发生丢包。

如上图所示,ECN 的交互过程描述如下:
- 发送端发送IP 报文标记ECN(ECN=10);
- 交换机在队列拥塞的情况下收到该报文,将ECN 字段修改为11 并转发出去;
- 接收服务器收到ECN 为11 的报文发送拥塞,正常处理该报文;
- 接收端产生拥塞通告,周期发送CNP(Congestion Notification Packets)报文,ECN字段为01,要求报文不能被网路丢弃;
- 交换机收到CNP 报文后正常转发该报文;
- 发送服务器收到ECN 标记为01 的CNP 报文解析后对相应的数据流限速算法;
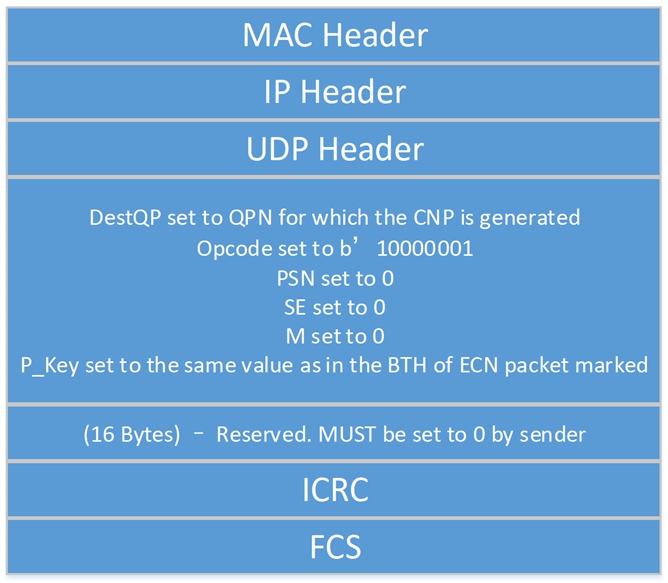
2.3.Fast ECN
当交换机队列中缓存数据包超过ECN阈值时,交换机会将拥塞信息标记报文的ECN字段,并携带到发送端服务器以通知其网络拥塞。接收端服务器接收到带有ECN字段的数据包后,发送CNP通知发送端服务器调整发送速率。
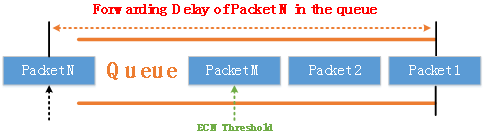
如上图所示,当数据报文进入队列排队时,传统的显式拥塞通知(ECN)判断队列使用的缓存是否超过ECN阈值。如果超过ECN阈值,交换机将数据报文IP头部中的ECN字段标记为11。发送端服务器接收带有ECN字段标记的数据报文的时间为交换机队列的数据包转发时间加上网络中标记的数据包转发时间。如果网络存在严重的网络拥塞,则ECN的反馈不及时可能会加剧队列拥塞。
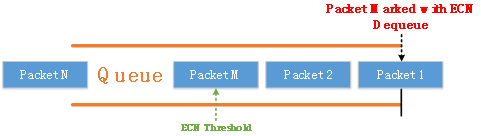
Fast ECN通过在数据报文出队列时,标记数据报文的ECN字段,从而缩短了入队列标记ECN的数据包转发时延,接收端服务器可以在最小的时延接收到ECN标记的数据报文,从而加快发送端速率的调整。
2.4.ETS
数据中心网络融合后,网络中存在三种流量:LAN流量、SAN流量和IPC流量。而
融合网络中对QoS 的要求更高,传统的QoS 已经无法满足融合网络的需求,而增强传输选择ETS(Enhanced Transmission Selection)通过灵活的层次化的调度实现网络融合后的QoS。

如上图所示,端口首先对优先级组进行第一级调度,然后对优先级组的优先级队列进行第二级调度。相比普通QoS,ETS 的优势在于提供了基于优先级组的调度,将同一类型的流量归入同一优先级组,使得同一类流量能够获得相同的服务等级。
优先级组即一组拥有相同调度方式的优先级队列,用户可通过设置将不同的优先级队列加入到优先级组中。基于优先级组的调度被称为第一级调度。
默认情况下,在ETS 中定义了3 个优先级组PG0、PG1 和PG15,分别代表是LAN 流量、SAN 流量和IPC 流量。
默认情况下,优先级组的属性如下表所示:

协议规定PG0、PG1 的调度方式是WFQ,PG15 的调度方式为是PQ。其中由于PG15
承载IPC 流量,对延时要求很高,因此调度方式为是PQ(Priority Queue);PG0 和PG1的调度方式为赤字轮循队列调度WFQ(Weighted Fair Queue)。
2.5.DCQCN
2015年SIGCOMM会上微软发表了DCQCN,揭开了拥塞流控的研究序幕。此前,RDMA硬件仅仅依赖于传统网络的PFC反压机制来实现点到点的发送速度控制,没有网卡的配合,无法实现端到端的流控。DCQCN是在QCN和DCTCP的技术基础上,为RDMA网络设计了端到端的拥塞流控机制。DCQCN的设计前提还是基于ECN标记,,无缝兼容现有以太网。DCQCN的拥塞控制过程中主要分为三部分:发送端(RP)调整流量发送速率,沿途转发交换机(CP)利用ECN标记报文携带网络链路的拥塞信息,接收端(NP)将收到拥塞标记通过CNP协议报文反馈给发送端。DCQCN在快速恢复阶段通过5个周期的更新即可恢复到原有速度,并且增加了一个激进加速阶段,使得DCQCN即使在低速情况下也能尽快调整到最佳发送速率。通过各种优化参数配置,DCQCN能实现很好的端到端拥塞控制效果,既能保证吞吐,和业务低时延。
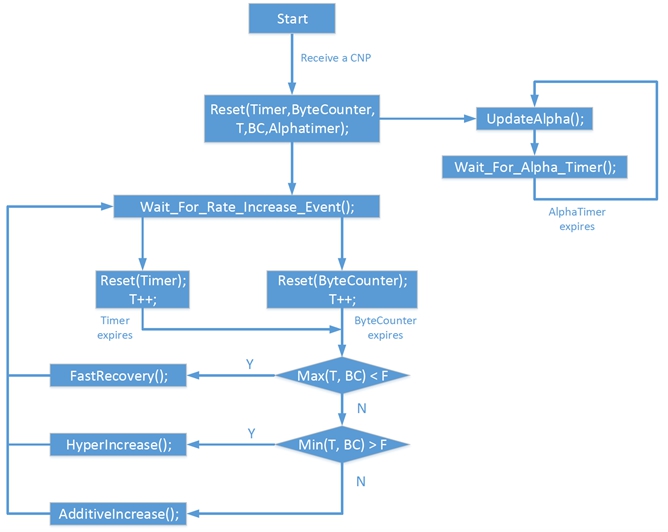
2.6.TIMELY
TIMELY是谷歌在2015年SIGCOMM会议上发表的。TIMELY利用了硬件智能网卡来测量RTT,刻意避免传统软件协议测量带来的误差,实现对RTT精确测量。与DCQCN不同的是,TIMELY借助的拥塞标记信号是RTT,而DCQCN是采用ECN。背靠智能网卡实现对RTT的精确测量,TIMELY获取拥塞信息的能力有了增强,利用RTT直接控制数据流发送速率的拥塞流控机制,发送端的速率计算也是以RTT为基础,计算加权移动平均后时延的变化率,通过量化的梯度方向即可根据论文中的公式计算出数据流的速率。
与通过TCP窗口控制发送的方法不同,TIMELY在数据报文之间插入发送时延从而控制数据流的发送速率,这能够降低数据报文突发Burst。在保障数据流低时延转发情况下,TIMELY能够保证链路高吞吐率和数据流之间的公平性。

2.7.HPCC
HPCC是阿里在2019年SIGCOMM上发表的,HPCC基于INT转发数据面,是对现有IP数据面的拥塞控制的替代方案,打破了过去的拥塞控制方案是建立在数据面不改动的原则。传统的拥塞控制算法主要依赖于丢包,RTT时延,以及ECN拥塞标识,发送端根据ECN等拥塞标记试探性调整发送速率,这可能导致网络收敛速度慢。当拥塞发生报文被标记指示路径拥塞程度字段时,交换机队列已缓存了一定数量的数据报文,此时再调整发送速率已经来不及了。同时,由于缺乏精准的拥塞信息,发送端试探性调整速率往往需要配合很多参数调优来保证性能,这也增加了在不同场景下的同一套流控机制调优的难度。
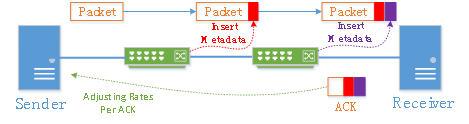
如上图所示,HPCC在数据面上找到了突破,通过智能网卡与交换机的配合,端到端实时抓取拥塞信息,从而精确获取实时的链路负载,并且根据精确的链路负载来计算合适的发送速率。与DCQCN依赖定时器驱动不同,HPCC速率调整根据数据包的ACK来驱动。HPCC借助更细粒度链路负载信息并重新设计了拥塞控制算法,能够在大规模网络下快速收敛、降低对大Buffer的依赖、保证数据流的公平性。
2.8.流控技术对比

3.流控技术方向与生态
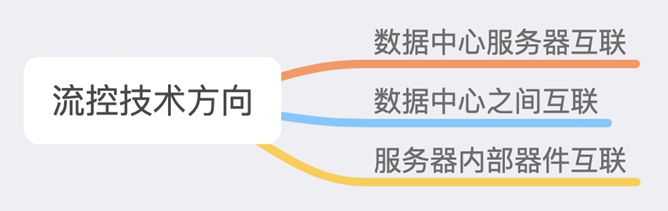
流控技术目前依然专注在数据中心服务器互联,集中力量在实现RDMA高性能的同时,扩大数据中心RDMA网络部署规模,最终完成存储计算网络的融合。
在完成数据中心内部RDMA互联后,数据中心之间互联有机会成为下一步攻坚点。换个视角往大里看,可以简单地将数据中心理解为计算节点,数据中心之间的互联链路就可以看作长距离的计算节点连线。虽然从原理上来看,可以等同,但距离从10m到100Km也引发了质变,对于现有的流控技术仍然是极大的挑战。再换个视角往小里看,在服务器内部的计算和存储的互联也可以利用更先进的无损网络,这里不能完全依赖流控技术,还需要可靠性的传输协议,目前这也是PCIe,IB擅长,而以太网需要加强的。。
总之,无论技术路线怎么走,无损网络与流控技术的春天正在向我们挥手。
4.流控技术生态
感谢ODCC无损网络工作组在提升数据中心网络性能和无损网络标准化工作中经年累月的全情投入,同伴们付出的坚卓努力正在一点一点突破性能极限。
参考资料和文献说明:
本文涉及的DCQCN,TIMELY,HPCC,RDMA等介绍参考了微软,谷歌,华为,阿里,迈络思等公司的相关文献,其他相关厂商这里不一一列举。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK