

Generalization in Deep Reinforcement Learning
source link: https://mc.ai/generalization-in-deep-reinforcement-learning/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Generalization in Deep Reinforcement Learning
{kind=link}
Overfitting in Supervised Learning
Machine learning is a discipline in which given some training data\environment, we would like to find a model that optimizes some objective, but with the intent of performing well on data that has never been seen by the model during training . This is usually referred to as Generalization , or the ability to learn something that is useful beyond the specifics of the training environment.
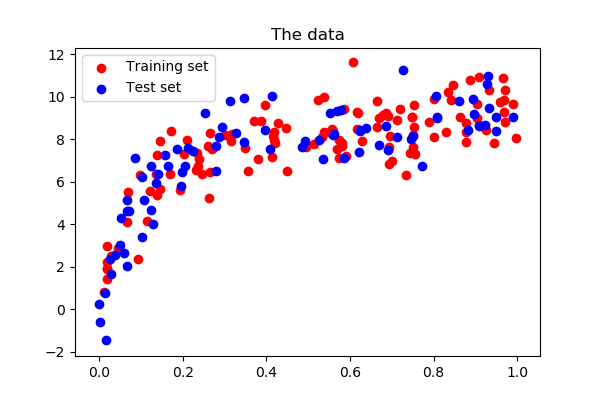
For this to be possible, we usually require that the training data distribution be representative of the real data distribution on which we are really interested in performing well. We split our data to train and test sets, and try to make sure that both sets represent the same distribution. This can be visualized easily in the supervised learning setting:
{kind=link}
we can see that while train and test samples are different, they are generated by the same underlying process. Had that not been the case, the standard concept of generalization in supervised learning would not hold, and it would be difficult to justify our expectation that learning on the training set should yield good results on the test set as well.
A common challenge in machine learning is avoiding Overfitting , which is a condition in which our model fits “too well” to the specifics and nuances of the training data, in a way that is detrimental to its performance on the test data.
In the example above, we can see that a sine-like curve (the black curve) gives a decent approximation to the data. When we split the data to train set (blue) and test set (red), we see that trying to fit the training set “too well” results in an orange curve that is obviously very different from the black curve and underperforms on the test set.
Overfitting in RL
In reinforcement learning, things are somewhat different. When considering the task of playing an Atari game as best as possible, it seems unclear that we can distinguish between some training environment and a test environment. If I train my agent to play “Breakout” and it performs well, wasn’t that the goal to begin with? This has been the situation in RL research until recently, and most research papers reported results on the same environment that the agent was trained on.
The first RL work to make the front page was the original DeepMind paper on learning to play Atari games using the ALE environment. ALE is deterministic, and a 2015 paper called “The Arcade Learning Environment: An Evaluation Platform For General Agents” showed that using a naïve trajectory optimization algorithm named “Brute” can yield state of the art results on some games. This algorithm does not even know what the current state is at any given moment, but it exploits the determinism in the environment to memorize successful sequences of actions. This raised the concern that some learned agents might be “memorizing” action sequences in some sense, and exploiting nuances of states to remember which action to take.
What does it mean for a neural network policy to memorize actions? When learning to play some game, we might like our policy to learn to avoid enemies, jump over obstacles and grab the treasure. Specifically, we would like our policy to jump over an enemy because there is an enemy nearby , and climb the ladder to the platform because it sees the treasure on the platform . In fully deterministic environments this might not be the case. Our policy might learn that it needs to jump at a certain point because of some visual feature on the background wall such as a unique tile texture or a painting, and learn to climb the ladder when it sees an enemy in a certain position on some distant platform.
These features occurring simultaneously with the desired features are a total coincidence, but because the environment is deterministic they might provide a stronger learning signal than those features we like our policy to base its decisions on.
{kind=link}
Subsequent papers have begun to explore ways to introduce stochasticity to the games, to discourage the agents from memorizing action sequences and instead learn more meaningful behaviors. Several other papers suggest that RL policies can be brittle to very minor mismatches between the environment they learn on and the one they are expected to be deployed in, making adoption of RL in the real world very difficult. We would like our policies to Generalize as they do in supervised learning, but what does it mean in the context of RL?
Generalization in RL
The goal in RL is usually described as that of learning a policy for an MDP that maximizes some objective function, such as the expected discounted sum of rewards. When we discuss generalization, we can propose a different formulation, in which we wish our policy to perform well on a distribution of MDPs. Using such as setup, we can now let the agent train on a set of MDPs and reserve some other MDPs as a test set.
In what way can these MDPs differ from each other? I see three key possible differences:
1. The states are different in some way between MDPs, but the transition function is the same. An example of this is playing different versions of a video game in which the colors and textures might change, but the behavior of the policy should not change as a result.
2. The underlying transition function differs between MDPs, even though the states might seem similar. An example of this some robotic manipulation tasks, in which various physical parameters such as friction coefficients and mass might change, but we would like our policy to be able to adapt to these changes, or otherwise be robust to them if possible.
3. The MDPs vary in size and apparent complexity, but there is some underlying principle that enables generalizing to problems of different sizes. Examples of this might be some types of combinatorial optimization problems such as the Traveling Salesman Problem, for which we would like a policy that can solve instances of different sizes.
In my opinion these represent the major sources of generalization challenge, but of course it’s possible to create problems that combine more than one such source. In what follows, I am going to focus on the first type.
Recently, researchers have begun to systematically explore generalization in RL by developing novel simulated environments that enable creating a distribution of MDPs and splitting unique training and testing instances. An example of such an environment is CoinRun , introduced by OpenAI in the paper “Quantifying Generalization in Reinforcement Learning” . This environment can produce a large variety of levels with different layouts and visual appearance, and thus serves as a nice benchmark for generalization.
{kind=link}
in this paper the authors examined the effect of several variables on the generalization capability of the learned policy:
Size of training set: the authors have shown that increasing the number of training MDPs increases the generalization capability, this can be seen:
as is the case in supervised learning, we can see that increasing the amount of training “data” makes it more difficult for the policy to succeed on the training set, but increases its ability to generalize to unseen instances.
Size of neural network: another finding from the paper that resonates with current practices in supervised learning, is that larger neural networks can often attain better generalization performance than smaller ones. The authors used the “standard” convolutional architecture from the DeepMind DQN paper (which they named “Nature-CNN”) and compared it with the architecture presented in DeepMind’s IMPALA paper. Results were significantly better using the larger model.
Regularization: the most common set of techniques used in supervised learning to improve generalization are things like L2 regularization, Dropout and Batch Normalization. These techniques constrict the neural network’s capacity to overfit by adding noise and decreasing the size of the weights, and have become a standard in supervised learning. Interestingly, they are not so common in the deep RL literature, as it is not always obvious that they help. In this paper however, the authors demonstrated that these techniques do help in improving generalization performance.
Overall, this paper presented a nice benchmark environment and examined common practices from supervised learning. But can we improve generalization even further?
Generalization with Random Networks
A very interesting paper called “A Simple Randomization Technique for Generalization in Deep Reinforcement Learning” presented a nice method to improve generalization over the standard regularization shown before. They suggest to add a convolutional layer just between the input image and the neural network policy, that transforms the input image. This convolutional layer is randomly initialized at each episode , and its weights are normalized so that it does not change the image too much. This works somewhat like data augmentation techniques, automatically generating a larger variety of training data.
the neural network policy is fed this augmented image and outputs the probability over actions as is usual in RL. Having a variety of visually different inputs should help the model learn features that are more general and less likely to overfit to visual nuances of the environment. This is commonly known as Domain Randomization and is often used to help bridge the gap between simulation and reality in robot applications of RL (I have written about it in another article). Unfortunately, domain randomization is known to suffer from high sample complexity and high variance in policy performance.
To mitigate these effects, the authors added another term to the loss; Feature Matching . This means that we give our model an original image and an augmented image (using the random layer), and encourage it to have similar feature for both by adding the mean squared error between them to the loss.
As a proof of concept, the authors first tried their method on a toy supervised learning problem; classifying cats and dogs. To make the problem challenging in terms of generalization, they created a training dataset with white dogs and black cats, and a test set with black dogs and white cats. They tested their method against the common regularization methods mentioned in the previous section, and some other data augmentation techniques from the image processing literature. The results are quite interesting:
In the RL setting, they tested their method against these baselines in several problems, including CoinRun, and achieved superior results in terms of generalization.
They performed an interesting experiment to check if their technique indeed creates features that are invariant to differences in visual appearance, by taking a sample trajectory in several visually different variations, and feeding it to a model trained without their and to a model trained with it. They then use dimensionality reduction to visualize the embeddings of these trajectories in the different models:
the numbers represent stages in the trajectory, and the colors represent visual variations of the states. It is evident that using the new technique, the states are much better clustered together in embedding space, suggesting that the model has indeed learned feature that are more invariant to these distracting visual variations.
I think this a very interesting line of research, which is crucial for wide spread adoption of deep reinforcement learning in industry. I hope to see more research in this direction.
Disclaimer: the views expressed in this article are those of the author and do not reflect those of IBM.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK