

科技网站最近有什么大新闻?LDA主题生成模型
source link: https://miketech.it/lda-topic?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

科技网站最近有什么大新闻?LDA主题生成模型
July 8, 2019
最近想给MikeTech加上相似文章的功能,也就是说,当你看完一篇文章时,网站会给你推荐类似的文章。这就需要用到主题模型了。刚好毕设也要用到这方面的知识,那么这篇文章将会讲述使用 LDA主题生成模型 来提取文章的主题。
提到主题模型,很多教程都是使用一些公共的数据集,比如Kaggle的 A Million News Headlines和 reddit 的新闻标题数据集,但是这些新闻太多了,有些词比较偏政治。所以这次我准备自己抓一点科技新闻网站的数据用好了。

那么就选择 TechCrunch 好了,比较老牌的科技新闻网站,高中的时候为了练英语经常看这个网站,而且刚好 TechCrunch 是前端异步请求文章的,分析了一下有现成的API可以用。所以就抓了从今天开始往前算的2000片文章。下面是Python的代码,只是简单地API请求和使用BeautifulSoup解析html获得文本,没什么需要特别解释的。
import requestsimport jsonfrom bs4 import BeautifulSouptitles = []contents = []page = 1while(page<=100):print('requesting page',page)url = 'https://techcrunch.com/wp-json/tc/v1/magazine?page=';url += str(page)response = requests.get(url)for i,each in enumerate(response.json()):title = each['title']['rendered']soup = BeautifulSoup(each['content']['rendered'])content = soup.get_text()titles.append(title)contents.append(content)page += 1def save_json(jsonObj, name):with open(name, 'w') as json_file:json.dump(jsonObj, json_file)print(name, 'saved')save_json(titles,'titles.json')save_json(contents,'contents.json')
通过上面的代码,我下载了2000篇文章的标题和内容分别保存为 titles.json 和 contens.json 文件。后来为了方便我将内容和标题结合起来保存为了 combined.json 文件。
下面是抓取的标题的一些实例:
- “Sony’s new wireless earbuds pack in great noise-canceling and battery life”
- “Image recognition, mini apps, QR codes: how China uses tech to sort its waste”
- “Clever Cloud launches GPU-based instances”
- “Smart scooter company Gogoro launches GoShare, an end-to-end vehicle sharing platform”
- “Waresix hauls in $14.5M to advance its push to digitize logistics in Indonesia”
- “PayU, Naspers’ global fintech firm, enters Southeast Asia with acquisition of Red Dot Payment”
- “Drifting champion tackles Goodwood with VR, 5G and one tiny startup’s tech”
- “UnitedMasters releases iPhone app for DIY cross-service music distribution”
可以看出来没什么问题,的确都是最新的科技文章。
Tokenization
那么接下来就需要对这 2000 篇文章进行预处理了,文本预处理最基本的就是分词 (tokenize) 了,英文的分词比中文的分词容易一些,根据空格进行分割就行,比如一句话 ‘He loves coding’。转换成小写并且分词就变成了 [‘he’, ‘loves’, ‘coding’]。
lemmatization and stemming 词干提取和词形还原
这个步骤是为了移除英文的语态,第三人称的词汇需要转换为第一人称词汇,比如 loves 需要转换成 love,否则 loves 和 love 就变成两个词了。
之后我们还需要把时态也移除掉,比如单词 wanted,coding会消除时态编程 want和code,当然有时候会使得词义变得不准确,比如code和coding还是有区别的,因为 he loves coding这句话中coding是一个动名词代表写代码。要解决这个问题就需要用到Word2vec了,以后再写吧。
移除Stop words
Stop words就是一些通常词汇,比如冠词 a, an, the等等,还有in, on, of 这些介词。再比如人称代词 he, she, it 之类的,这些词汇在一篇英文文章中占绝大多数,但是却对文章的主题和内容贡献不大。所以需要过滤掉
根据长度过滤
预处理英文的时候一般也会过滤掉长度小于3的单词,因为长度小于3的单词大部分情况下没有什么意义,比如语气词 ’Ahh’ 之类的。
上面的这些过滤方法可以使用Python的自然语言处理库 NLTK 来实现
import gensimfrom gensim.utils import simple_preprocessfrom gensim.parsing.preprocessing import STOPWORDSfrom nltk.stem import WordNetLemmatizer, SnowballStemmerfrom nltk.stem.porter import *import numpy as npnp.random.seed(2018)import nltknltk.download('wordnet')# lemmatize and stemmingstemmer = SnowballStemmer("english")def lemmatize_stemming(text):return stemmer.stem(WordNetLemmatizer().lemmatize(text, pos='v'))def preprocess(text):result = []for token in gensim.utils.simple_preprocess(text):if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) >= 3:result.append(lemmatize_stemming(token))return result
我们就拿第一篇文章的标题 “Sony’s new wireless earbuds pack in great noise-canceling and battery life” 来预处理一下。

可以看出来 Sony’s 变成了 sony,介词连词 in 和 and被去掉了。在这里我没有使用stemmer进行处理,因为NLTK的stemmer效果很一般有时候词会变得很诡异比如 Apples 边单数应该是 apple, 但是 stemmer 有时候会移除es变成 appl, 所以我还是不用这步操作了。
词袋模型 BOW
那么接下来就需要对每篇文章进行一个建模了。文本处理一般最简单的模型就是词袋模型 (bag of words, a.k.a BOW) 了,通俗的讲,通过词袋模型可以把一篇文章转换成一个向量。那么怎么样才能生成一个词袋模型呢,首先需要先建立一个字典 。字典就是所有可能词汇的集合。比如我想给两个句子建立词袋模型: “He loves coding” 和 “She loves programming”。那么字典就应该是两个句子分词后的并集: [he, loves, coding, she, programming]. 那么BOW向量就是字典中对应的每个词的出现次数 (也就是词频,term frequency)。第一个句子是 [1,1,1,0,0],第二个句子则为 [0,1,0,1,1]。BOW是非常简单的模型但是还是有效果的。也就是说,一个文章的词频向量就是字典上的词的一个直方图。
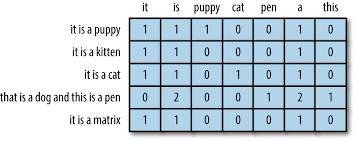
Image Reference: 4. The Effects of Feature Scaling: From Bag-of-Words to Tf-Idf - Feature Engineering for Machine Learning Book
当然仅仅使用BOW还有一些缺点,比如在BOW中的词是不分顺序的,也就是说 “I hate you” 和 “You hate I” 是没有区别的。用N-gram模型能够解决这一问题。还有就是刚才提到的英文中有的词汇意思相近的问题,上面的例子 coding和programming明显就是一个意思的,所以需要提升的话前期分词的时候还需要做一些处理。
刚才提到了BOW向量其实就是词频的一个向量,如果需要用到这个向量做相似的比较的时候,需要对这个向量进行归一化处理。为什么呢,因为文章的长度不同,文章很长的话,某一个词的词频肯定大,文章短的话那个词的词频肯定相对小。所以说一般要把词频向量除以那个文章的总字数做归一化操作,当然这里用不到啦。
还需要注意的是,因为一篇文章不可能包含字典里面所有的词,所以词频向量是一个非常稀疏的向量。
Genism 可以直接生成字典和BOW向量,最后还需要生成文档语料库。
# Bag of Wordsdictionary = gensim.corpora.Dictionary(processed_docs)# Filter out tokens# less than 15 documnents# more than 50% of documents# Then keep the first 100000 most frequent tokensdictionary.filter_extremes(no_below=15, no_above=0.5, keep_n=len(dictionary))# doc2bowbow_corpus = [dictionary.doc2bow(doc) for doc in processed_docs]
TF-IDF 模型
TF-IDF是在词袋模型的基础上演化过来的,因为在一些情况下BOW并不能很好的找出一个文章的关键词。比如TechCrunch上面的那么多文章。其中一篇文章Company这个词出现的特别多,在词袋模型中会被认为Company是这个文章的主题词汇,但是事实上在TechCrunch的文章中大多数文章Company这个词都出现的很多,所以这样的词汇不应该被认作是关键词汇,使用TF-IDF模型可以避免这个问题。
下面的图则为一个词在一篇文章中的TF-IDF计算公式;
- TF(Term frequency) 代表词频,就是词语出现的次数
- IDF (Inverse document frequency) 代表逆文档率,是这个词汇出现文章的个数除以文章的总数再取log
- TF-IDF值则为 TF 乘以 IDF
原理也很好解释,比如一个词的词频是 100,总共有100篇文章,100篇都有这个词,此时 IDF = log(100/100) = 0, 即使这个词词频再高,那么TF-IDF计算出来也是0。而如果100篇文章中只有1篇出现了这个词那么IDF=2,TF-IDF值会变大,代表这个词的权重更大。

Image reference: 中文文本探勘初探:TF-IDF in R Language | Mr. Opengate
当然Genism库也是可以直接计算TF-IDF模型的:
# TF-IDFfrom gensim import corpora, modelstfidf = models.TfidfModel(bow_corpus)corpus_tfidf = tfidf[bow_corpus]
LDA模型训练
LDA(Latent Dirichlet allocation)是文档主题生成模型,是根据概率分布来对文章主题进行聚类的一个模型,关于LDA的原理,英文好的人可以去读提出时候的论文: Latent Dirichlet Allocation,在这里简单的说一下,对文章语料库进行LDA之后会获得一系列主题,主题的个数是训练的时候确定的,每个主题包含若干词汇。之后的演示中还会提到。
Genism也能直接训练LDA模型:
在这里我规定了主题数为10个,在下面的例子中我使用了词袋模型进行训练而没有使用TF-IDF,至于为什么以后会写文章讨论。其他的参数不懂得可参考官方的文档 gensim: models.ldamulticore – parallelized Latent Dirichlet Allocation
lda_model_tfidf = gensim.models.LdaMulticore(bow_corpus,num_topics=10,id2word=dictionary,passes=10,iterations=50,workers=8)
生成了LDA之后可以可视化一下来看看结果如何,在这里我使用了 pyLDAvis 来对genism的LDA模型进行可视化:
import pyLDAvis.gensimlda_display = pyLDAvis.gensim.prepare(lda_model_tfidf, bow_corpus, dictionary, sort_topics=True)pyLDAvis.display(lda_display)
下图是所有文章中最突出的30个词汇,因为我是用BOW模型进行训练的,所以下图应为词频最高的30个词汇,既然TechCrunch是个科技网站,那么这些词汇看起来没有问题,Apple,Google,Amazon,Facebook,Huawei都是名列前茅的词汇。
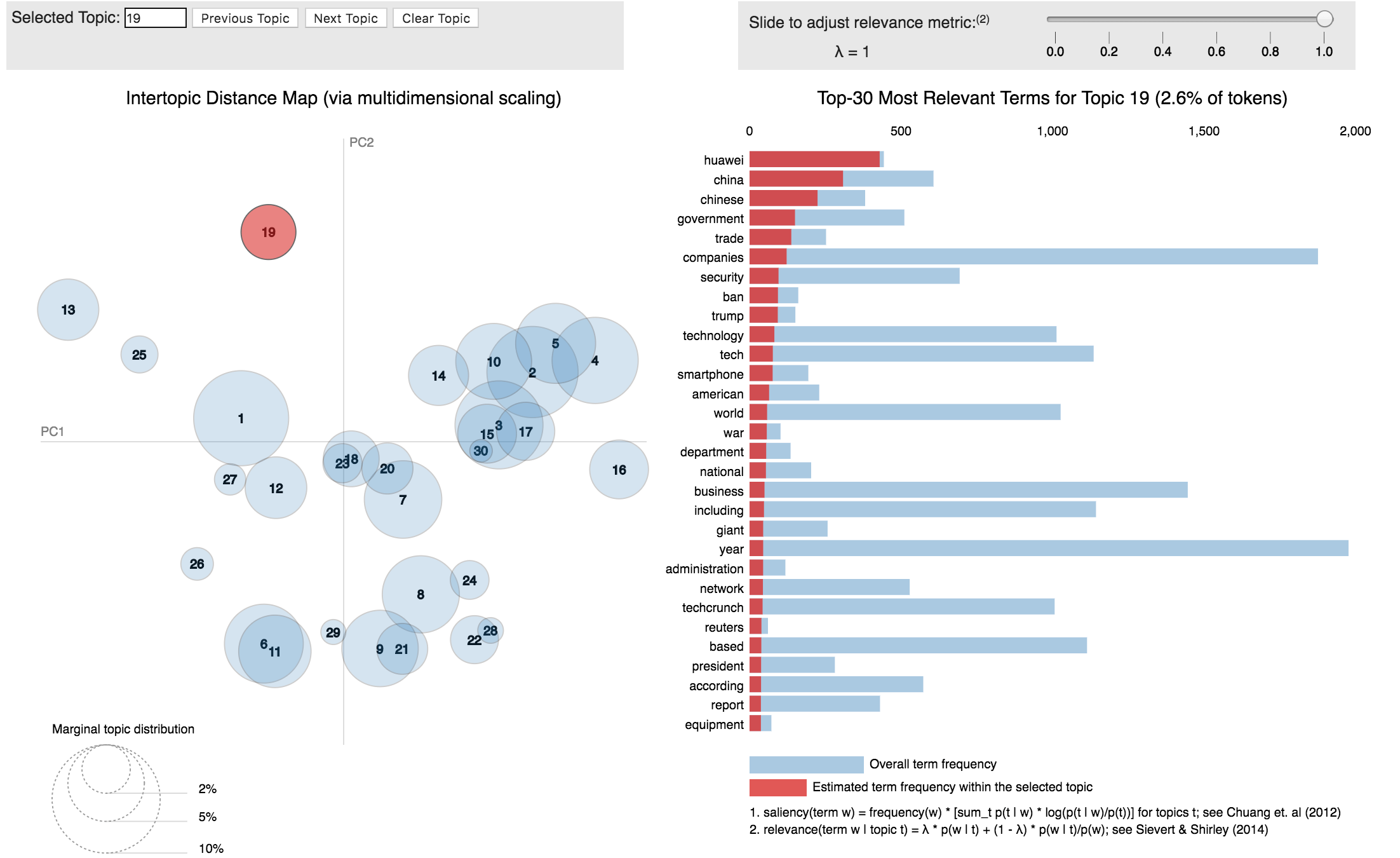
下图是所有主题的一个总览,这里我训练的时候设置了主题为20个,可视化之后看出来很多主题都有互相重合,不过结果并没有问题,那下面的主题19来举例子:
主题19的核心词汇为 Huawei,在所有文章中19主题相关的文章出现华为的次数最多,其他的词汇也是相关的,这个主题19可以看出来是对应了最近的华为事件,从其中的词汇 China(中国),Ban(禁令),Security(安全),Trump(川普),Trade(贸易)就可以看出来。
来打印一下主题19相关的文章,可以看出来的确主题19的相关文章都是关于华为禁令的。

如果将topic数目设为10可以得到下面的结果,这样不同的主题重合就很少了:
我粗略的看了下这10个主题,TechCrunch的进2000片文章讲述的一般都是:
苹果,
- SpaceX的太空计划(前些日子的星链条部署),
- Facebook和Google的隐私问题
- Amazon退出中国市场
- 初创公司的现状
- 华为: 这个主题在空间上和 Facebook隐私问题挨得很近,因为这两个主题都反映了安全问题。
的确,最近科技圈是差不多是这些新闻。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK