

RedShift Unload All Tables To S3
source link: https://www.tuicool.com/articles/VvmAZvE
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

RedShift unload
function will help us to export/unload the data from the tables to S3 directly. It actually runs a select query to get the results and them store them into S3. But unfortunately, it supports only one table at a time. You need to create a script to get the all the tables then store it in a variable, and loop the unload query with the list of tables. Here I have done with PL/SQL way to handle this. You can Export/Unload all the tables to S3 with partitions.
If you didn’t take a look at how to export a table with Partition and why? Pleasehit here and read about the importance of it.
Why this procedure actually doing?
information_schema FOR LOOP
Variables:
- list - list of schema and table names in the database.
- db - Current connected database name.
- tablename - table name (used for history table only).
- tableschema - table schema (used for history table only).
- starttime - When the unload the process stated.
- endtime - When the unload process end.
-
SQL - its a
select * from, but if you want to change likewhere timestamp >= somethingyou can customize this variable. - s3_path - Location of S3, you need to pass this variable while executing the procedure.
- iamrole - IAM role to write into the S3 bucket.
- delimiter - Delimiter for the file.
- max_filesize - Redshift will split your files in S3 in random sizes, you can mention a size for the files.
- un_year, un_month, un_day - Current Year, month, day
- unload_query - Dynamically generate the unload query.
- unload_id - This is for maintaining the history purpose, In one shot you can export all the tables, from this ID, you can get the list of tables uploaded from a particular export operation.
- unload_time - Timestamp of when you started executing the procedure.
NOTE: This stored procedure and the history table needs to installed on all the databases. Because from information schema it’ll only return the list of tables in the current schema. Its Redshift’s limitation.
Table for maintaining the History of Unload:
CREATE TABLE unload_history ( pid INT IDENTITY(1, 1), u_id INT, u_timestamp DATETIME, start_time DATETIME, end_time DATETIME, db_name VARCHAR(100), table_schema VARCHAR(100), table_name VARCHAR(100), export_query VARCHAR(10000) );
Stored Procedure:
CREATE OR replace PROCEDURE unload_all(s3_location TEXT) LANGUAGE plpgsql
AS
$$
DECLARE
list RECORD;
db VARCHAR(100);
tablename VARCHAR(100);
tableschema VARCHAR(100);
starttime datetime;
endtime datetime;
SQL text;
s3_path VARCHAR(1000);
iamrole VARCHAR(100);
delimiter VARCHAR(10);
max_filesize VARCHAR(100);
un_year INT;
un_month INT;
un_day INT;
unload_query text;
unload_id INT;
unload_time timestamp;
BEGIN
-- Pass values for the variables
SELECT extract(year FROM getdate())
INTO un_year;
SELECT extract(month FROM getdate())
INTO un_month;
SELECT extract(day FROM getdate())
INTO un_day;
SELECT DISTINCT(table_catalog)
FROM information_schema.TABLES
INTO db;
SELECT coalesce(max(u_id), 0)+1
FROM unload_history
INTO unload_id;
SELECT getdate()
INTO unload_time;
s3_path:=s3_location;
-- IAM ROLE and the Delimiter is hardcoded here
iamrole:='arn:aws:iam::123123123123:role/myredshiftrole';
delimiter:='|';
-- Get the list of tables except the unload history table
FOR list IN
SELECT table_schema,
table_name
FROM information_schema.TABLES
WHERE table_type='BASE TABLE'
AND table_schema NOT IN ('pg_catalog',
'information_schema')
AND table_name !='unload_history' LOOP
SELECT getdate()
INTO starttime;
sql:='select * from '||list.table_schema||'.'||list.table_name||'' ;
RAISE info '[%] Unloading... schema = % and table = %',starttime, list.table_schema, list.table_name;
-- Start unloading the data
unload_query := 'unload ('''||sql||''') to '''||s3_path||un_year||'/'||un_month||'/'||un_day||'/'||list.table_schema||'/'||list.table_name||'/'||list.table_schema||'-'||list.table_name||'_'' iam_role '''||iamrole||''' delimiter '''||delimiter||''' MAXFILESIZE 100 MB PARALLEL ADDQUOTES HEADER GZIP';
EXECUTE unload_query;
SELECT getdate()
INTO endtime;
SELECT list.table_schema
INTO tableschema;
SELECT list.table_name
INTO tablename;
-- Insert into the history table
INSERT INTO unload_history
(
u_id,
u_timestamp,
start_time,
end_time,
db_name,
table_schema,
table_name,
export_query
)
VALUES
(
unload_id,
unload_time,
starttime,
endtime,
db,
tableschema,
tablename,
unload_query
);
END LOOP;
RAISE info ' Unloading of the DB [%] is success !!!' ,db;
END;
$$;
Hardcoded Items:
In the stored procedure, I have hardcoded the follow parameters.
arn:aws:iam::123123123123:role/myredshiftrole |
Also, the following Items are hardcoded in the Unload query. You can get these things as variable or hardcoded as per your convenient.
- MAXFILESIZE - 100 MB
- PARALLEL
- ADDQUOTES
- HEADER
- GZIP
Execute the procedure:
call unload_all('s3://bhuvi-datalake/test/');
You can see the status in the terminal
INFO: [2019-10-06 19:20:04] Unloading... schema = etl and table = tbl1 INFO: UNLOAD completed, 2 record(s) unloaded successfully. INFO: [2019-10-06 19:20:10] Unloading... schema = etl and table = tbl2 INFO: UNLOAD completed, 2 record(s) unloaded successfully. INFO: [2019-10-06 19:20:12] Unloading... schema = stage and table = tbl3 INFO: UNLOAD completed, 2 record(s) unloaded successfully. INFO: [2019-10-06 19:20:12] Unloading... schema = stage and table = tbl4 INFO: UNLOAD completed, 2 record(s) unloaded successfully. INFO: [2019-10-06 19:20:14] Unloading... schema = stage and table = tbl5 INFO: UNLOAD completed, 2 record(s) unloaded successfully. INFO: [2019-10-06 19:20:15] Unloading... schema = prod and table = tbl6 INFO: UNLOAD completed, 2 record(s) unloaded successfully. INFO: [2019-10-06 19:20:15] Unloading... schema = prod and table = tbl7 INFO: UNLOAD completed, 2 record(s) unloaded successfully. INFO: [2019-10-06 19:20:15] Unloading... schema = public and table = debug INFO: UNLOAD completed, 0 record(s) unloaded successfully. INFO: [2019-10-06 19:20:16] Unloading... schema = public and table = test INFO: UNLOAD completed, 1 record(s) unloaded successfully. INFO: Unloading of the DB [preprod] is success !!! CALL
Files on S3:
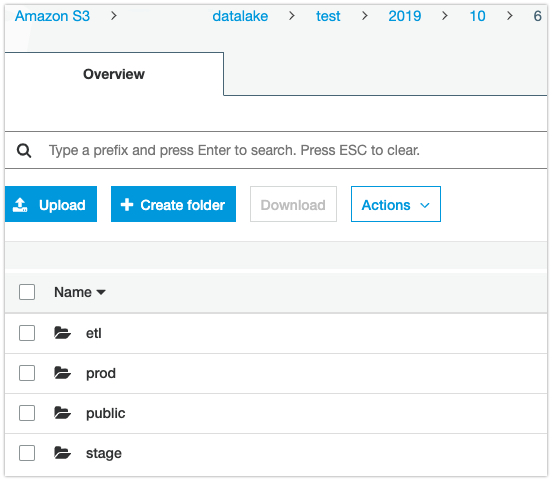
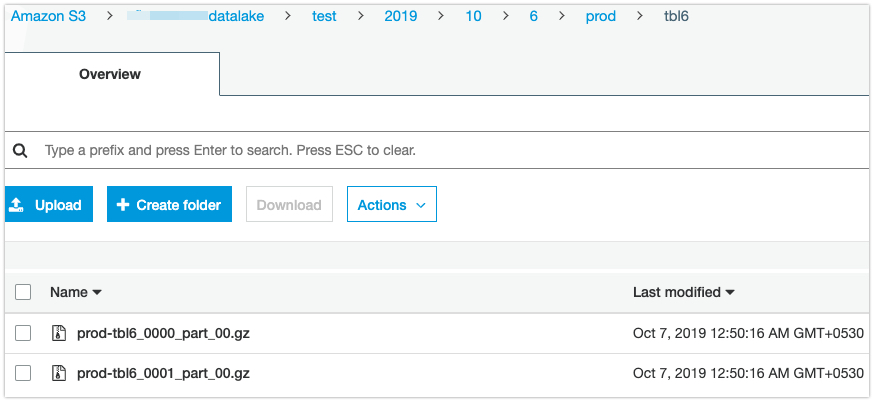
Retrieve the History:
preprod=# select * from unload_history limit 1;
pid | 1
u_id | 1
u_timestamp | 2019-10-06 19:20:04
start_time | 2019-10-06 19:20:04
end_time | 2019-10-06 19:20:05
db_name | preprod
table_schema | etl
table_name | tbl1
export_query | unload ('select * from etl.tbl1') to 's3://bhuvi-datalake/test/2019/10/6/etl/tbl1/etl-tbl1_' iam_role 'arn:aws:iam::123123123:role/myredshiftrole' delimiter '|' MAXFILESIZE 100 MB PARALLEL ADDQUOTES HEADER GZIP
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK