

FileStorm的共识机制 | 深入浅出区块链 | 技术博客
source link: https://learnblockchain.cn/2019/09/01/filestorm/?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

FileStorm 的共识机制
首先 FileStorm 有出块节点和存储节点两种不同节点。而出块验证和存储验证用的是两个不同的共识。
FileStorm 区块链出块验证采用的是 dPOS,Delegated Proof of Stake,或称委托权益证明共识机制。它是由选出来的验证节点(俗称超级节点)轮流打包块,并对其他节点出的区块进行验证。DPOS 利用利益相关方批准投票的权力以公平和民主的方式解决共识问题。 是目前所有共识协议中最快,最有效,最分散,最灵活的共识模式。
FileStorm 的文件验证采用的是类似 PBFT,或称实用拜占庭容错的共识。实用拜占庭容错共识的核心是,所有节点中不能有超过三分之一的坏节点,在 n>=3f+1 的前提下,可以通过少量的信息交换达成共识。信息传递的方式可用下图表示。
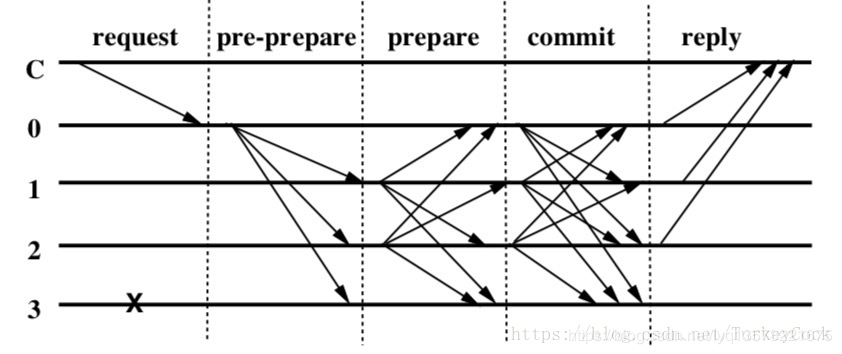
存储、分片
FileStorm 中的存储节点会被分到不同的分片(Shard)中,分片是最基本的一个存储空间单位,就相当于数据库里的一个分片。每个分片里的存储节点硬盘一样大,存的文件也是一样。这样一个分片里的各个节点之间在 n>=3f+1 的前提下可以互相验证。所有的文件的信息和读写交易都写在区块链上,而文件内容则存在存储节点的 IPFS 中。所以 FileStorm 平台上会有很多的分片。分片里的每个节点都会定期做文件的时空复制证明。
那一个分片里的存储节点之间是怎样通过类 PBFT 共识来做验证的呢?首先被验证节点要根据自己存储的文件和一个计算方法做一道数学题,然后提交自己的答案;而分片里其他节点也要用同样的文件和计算方法来做题得到答案,拿这个结果跟提交的答案比较以后进行投票。如果有超过半数的人投票自己的结果和被验证节点一样,说明被验证节点是诚实节点,并且存了该存的文件。
分片中每个节点存储文件相同,计算方式相同,那怎么样才能保证每次出的考题不一样,让存储节点没有办法作弊呢?这时候,就要请出超级节点来当出题老师了。
但实际上超级节点也不是出题老师。他只是监考老师。出题老师是 FileStorm 区块链本身。FileStorm 每个区块的区块头上有两个随机数。这两个随机数的产生跟出块的时间和上一个区块哈希有关,所以很难被作弊。就是这两个随机数,决定了存储验证的计算应该怎么做。详解如下:
存储节点定期对本地文件进行验证。轮到验证时,它会从当前区块头里拿到这两个随机数。用第一个随机数,它从自己的本地文件中随机找到一组文件,然后用第二个随机数找到每个文件中的一个随机的起始位置。从这个起始位置往后数 256 个字节,便得到一组随机的字符串组。先对每个文件中的这组字符串进行哈希,然后将哈希结果两两哈希,直到得出一个根哈希值。这就是验证节点要提交的答案。两个随机数保证了每次提交验证的结果是不同的。
同时,同分片里的其他节点也要做同样的操作。因为他们拿到的随机数是一样的,计算方法也一样,如果文件跟被验证节点一样,那得到的哈希值就是一样的。被验证节点先将自己的哈希值以交易的方式发到链上。其他节点收到交易后,跟自己生成的哈希进行比较,然后将比较结果也以交易的方式发出来。最后进行统计,如果超过半数的节点给出的哈希值跟被验证节点相同。我们认为被验证节点存了所有的文件,我们就会给它奖励。
以上就是文件复制的空间证明。用随机数选取部分文件进行验证可以大大降低文件验证时耗费的资源。
文件复制的时间证明也是通过区块决定。每个存储节点都有一个最后验证区块高度的参数,然后系统里有一个文件验证的频率参数。频率参数暂时设定为 1000。每天 FileStorm 区块链要产生大约 8640 个区块,也就是说,每天每个存储节点都要被验证 8 次。最后验证区块高度参数记录了这个节点上次被验证的区块高度,一旦当前区块高度多出 1000,就要做存储验证,并更新最后验证区块高度。分片中每个节点都知道其他节点的最后验证区块高度。所以会在该投票的时候为被验证节点投票。
PBFT 共识最少需要 4 个节点来参与。FileStorm 分片的大小,现在设定为 7 到 10,是符合 PBFT 共识要求的。但这可能是 FileStorm 一个最有争议的地方。有人认为文件存储这么多份,造成了资源浪费。我们不这么认为,理由如下:
我们认为,在一个去中心化的分布式系统中,节点的可靠性只有中心化分布式系统的 30%-50%,中心化存储平台如 Hadoop 会将文件存 3 份,我们存 7 到 10 份是合理的。这个数字将来在分布式存储系统的稳定性和鲁棒性加强后可以做调整。
现在还没有被市场检验过的大型商用去中心化平台,而为去中心化存储生产出来的存储设备明显高于去中心化存储需求量。我们早期完全可以这样做,确保文件不被丢失。
去中心化存储的成本会比中心化低本身就是一个伪命题,有人认为中心化存储和云存储服务商都有大量资产配置冗余,而去中心化平台有早期平台发放加密货币带来的使用红利。但是真正的数据比较还没有人做过。
最后还要补充两点,首先,分片里的存储节点是全网随机选取的,没有可能互相认识,也就没有作弊的动机。验证所用的随机数是区块链产生的随机数,也没法被存储节点用来作弊。第二,系统自带修复机制,节点每次验证时其实还要做文件检查和同步,如果有文件缺损,就会补上。节点下线,就会有新节点加进来。
本文内容来自 FileStorm 创始人献哥。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK