

互联网公司面试经——你不得不知道的哈希表 - 崖边小生
source link: https://www.cnblogs.com/hunternet/p/11324945.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

文章导航-readme#
前言#
哈希表,又名散列表。是非常常用的一种数据结构,C#的Hashtable、字典,Java的HashMap,Redis的Hash,其底层实现都是散列表。而在一些互联网公司的面试中,更是技术面试官们必问的一道题目。本文将简单了解哈希表(散列表)这种数据结构。
一、散列表#
1.1 散列表#
散列表(哈希表),其思想主要是基于数组支持按照下标随机访问数据时间复杂度为O(1)的特性。可是说是数组的一种扩展。假设,我们为了方便记录某高校数学专业的所有学生的信息。要求可以按照学号(学号格式为:入学时间+年级+专业+专业内自增序号,如2011 1101 0001)能够快速找到某个学生的信息。这个时候我们可以取学号的自增序号部分,即后四位作为数组的索引下标,把学生相应的信息存储到对应的空间内即可。
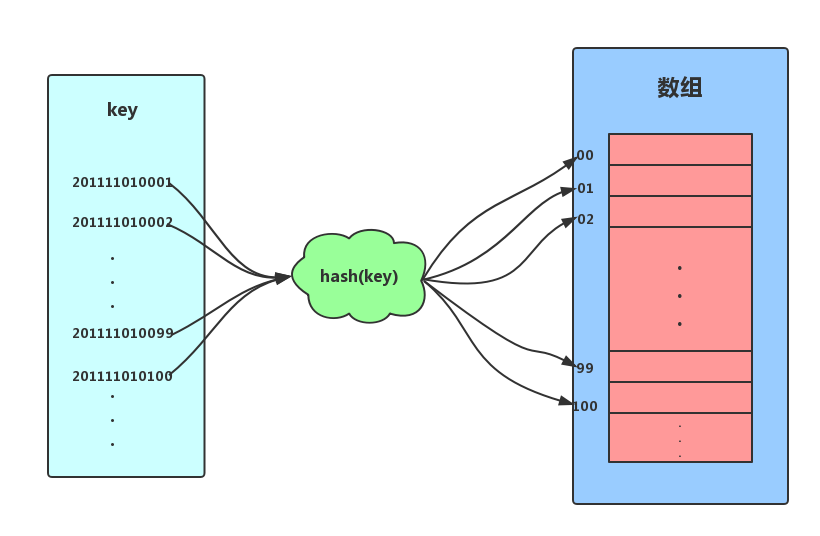
如上图所示,我们把学号作为key,通过截取学号后四位的函数后计算后得到索引下标,将数据存储到数组中。当我们按照键值(学号)查找时,只需要再次计算出索引下标,然后取出相应数据即可。以上便是散列思想。
1.2 散列函数#
上面的例子中,截取学号后四位的函数即是一个简单的散列函数。
//散列函数 伪代码
int Hash(string key) {
// 获取后四位字符
string hashValue =int.parse(key.Substring(key.Length-4, 4));
// 将后两位字符转换为整数
return hashValue;
}
在这里散列函数的作用就是讲key值映射成数组的索引下标。关于散列函数的设计方法有很多,如:直接寻址法、数字分析法、随机数法等等。但即使是再优秀的设计方法也不能避免散列冲突。在散列表中散列函数不应设计太复杂。
1.3 散列冲突#
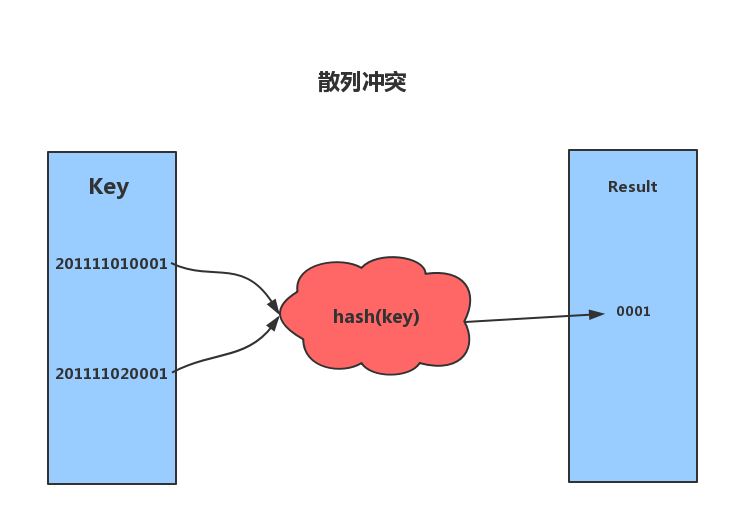
散列函数具有确定性和不确定性。
- 确定性:哈希的散列值不同,那么哈希的原始输入也就不同。即:key1=key2,那么hash(key1)=hash(key2)。
- 不确定性:同一个散列值很有可能对应多个不同的原始输入。即:key1≠key2,hash(key1)=hash(key2)。
散列冲突,即key1≠key2,hash(key1)=hash(key2)的情况。散列冲突是不可避免的,如果我们key的长度为100,而数组的索引数量只有50,那么再优秀的算法也无法避免散列冲突。关于散列冲突也有很多解决办法,这里简单复习两种:开放寻址法和链表法。
1.3.1 开放寻址法
开放寻址法的核心思想是,如果出现了散列冲突,我们就重新探测一一个空闲位置,将其插入。比如,我们可以使用线性探测法。当我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,如果遍历到尾部都没有找到空闲的位置,那么我们就再从表头开始找,直到找到为止。
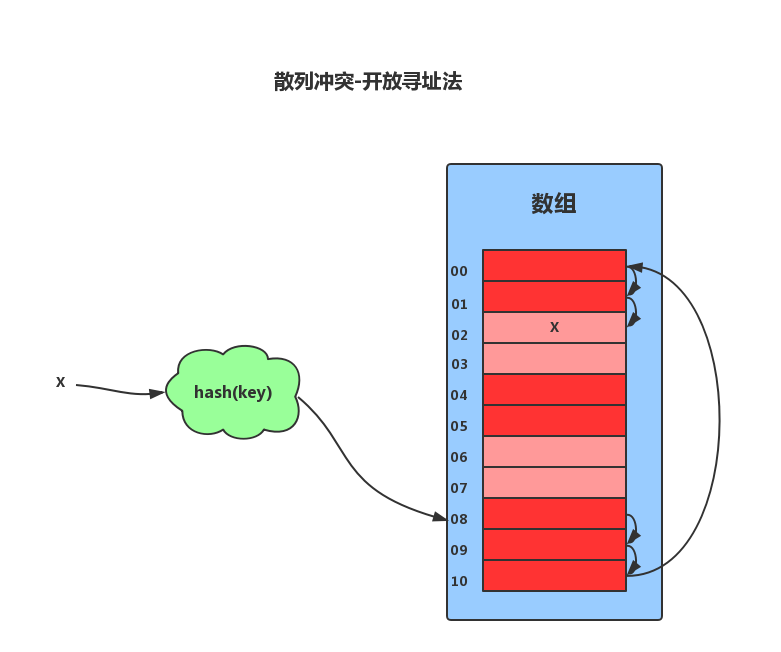
散列表中查找元素的时候,我们通过散列函数求出要查找元素的键值对应的散列值,然后比较数组中下标为散列值的元素和要查找的元素。如果相等,则说明就是我们要找的元素;否则就顺序往后依次查找。如果遍历到数组中的空闲位置还没有找到,就说明要查找的元素并没有在散列表中。
对于删除操作稍微有些特别,不能单纯地把要删除的元素设置为空。因为在查找的时候,一旦我们通过线性探测方法,找到一个空闲位置,我们就可以认定散列表中不存在这个数据。但是,如果这个空闲位置是我们后来删除的,就会导致原来的查找算法失效。这里我们可以将删除的元素,特殊标记为 deleted。当线性探测查找的时候,遇到标记为 deleted 的空间,并不是停下来,而是继续往下探测。
线性探测法存在很大问题。当散列表中插入的数据越来越多时,其散列冲突的可能性就越大,极端情况下甚至要探测整个散列表,因此最坏时间复杂度为O(N)。在开放寻址法中,除了线性探测法,我们还可以二次探测和双重散列等方式。
1.3.2 链表法(拉链法)
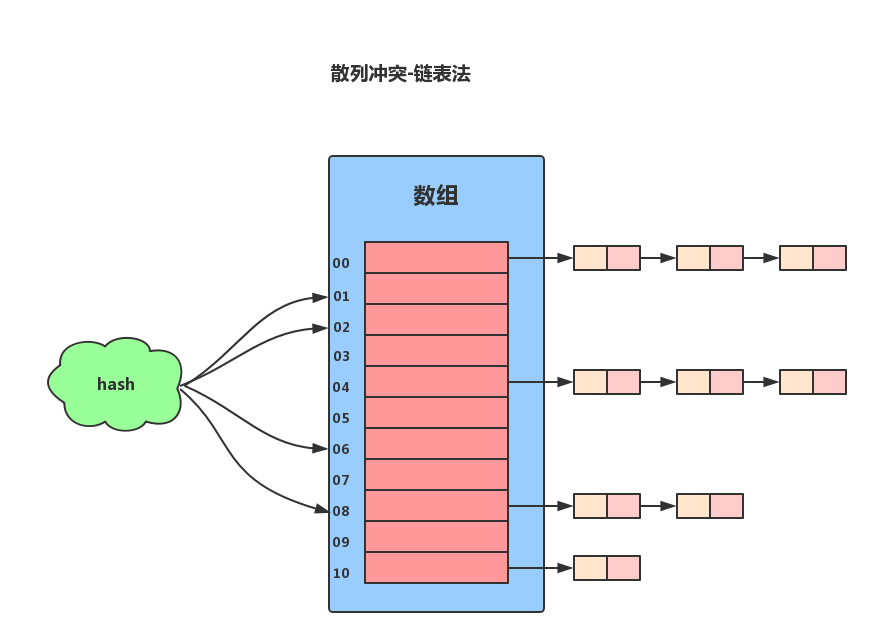
简单来讲就是在冲突的位置拉一条链表来存储数据。
链表法是一种比较常用的散列冲突解决办法,Redis使用的就是链表法来解决散列冲突。链表法的原理是:如果遇到冲突,他就会在原地址新建一个空间,然后以链表结点的形式插入到该空间。当插入的时候,我们只需要通过散列函数计算出对应的散列槽位,将其插入到对应链表中即可。
1.3.3 负载因子与rehash
我们可以使用装载因子来衡量散列表的“健康状况”。
散列表的负载因子 = 填入表中的元素个数/散列表的长度
散列表负载因子越大,代表空闲位置越少,冲突也就越多,散列表的性能会下降。
对于散列表来说,负载因子过大或过小都不好,负载因子过大,散列表的性能会下降。而负载因子过小,则会造成内存不能合理利用,从而形成内存浪费。因此我们为了保证负载因子维持在一个合理的范围内,要对散列表的大小进行收缩或扩展,即rehash。散列表的rehash过程类似于数组的收缩与扩容。
1.3.4 开放寻址法与链表法比较
对于开放寻址法解决冲突的散列表,由于数据都存储在数组中,因此可以有效地利用 CPU 缓存加快查询速度(数组占用一块连续的空间)。但是删除数据的时候比较麻烦,需要特殊标记已经删除掉的数据。而且,在开放寻址法中,所有的数据都存储在一个数组中,比起链表法来说,冲突的代价更高。所以,使用开放寻址法解决冲突的散列表,负载因子的上限不能太大。这也导致这种方法比链表法更浪费内存空间。
对于链表法解决冲突的散列表,对内存的利用率比开放寻址法要高。因为链表结点可以在需要的时候再创建,并不需要像开放寻址法那样事先申请好。链表法比起开放寻址法,对大装载因子的容忍度更高。开放寻址法只能适用装载因子小于1的情况。接近1时,就可能会有大量的散列冲突,性能会下降很多。但是对于链表法来说,只要散列函数的值随机均匀,即便装载因子变成10,也就是链表的长度变长了而已,虽然查找效率有所下降,但是比起顺序查找还是快很多。但是,链表因为要存储指针,所以对于比较小的对象的存储,是比较消耗内存的,而且链表中的结点是零散分布在内存中的,不是连续的,所以对CPU缓存是不友好的,这对于执行效率有一定的影响。
小结#
对于一些一线城市的互联网公司,技术面试官比较喜欢考察一个人的基础,像哈希这种经典而又应用广泛的数据结构更是老生常谈之题目。大致提问方式无非以下几种
- C#字典(java hashmap或者Redis hash)的底层实现方式
- 说一下什么是哈希表(散列表)
- 哈希如何解决碰撞(散列如何解决冲突)
-----END-----#
感谢大家阅读,如有问题可在文章下方留言,我会在第一时间回复!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK