

FD.io——助你创新更高效、更灵活的报文处理方案
source link: https://www.sdnlab.com/23064.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
作者简介:倪红军,Intel 网络软件工程师
FD.io项目早期贡献者
VPP Maintainer/Sweetcomb Project Lead
NSH_SFC Project Lead/Hc2vpp Committer
文章转载自DPDK与SPDK开源社区
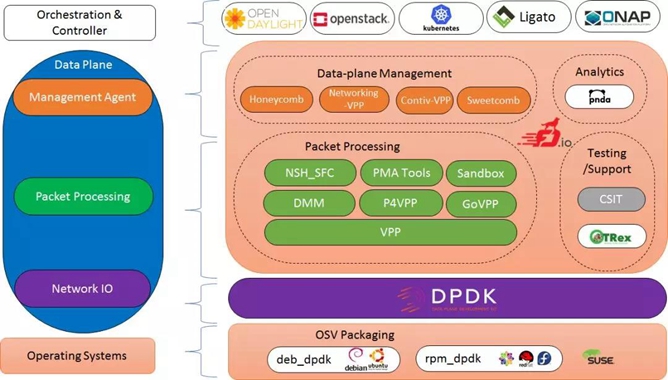
FD.io (Fast data – Input/Output) 是许多项目和库的一个集合,基于DPDK并逐渐演化,支持在通用硬件平台上部署灵活和可变的业务。FD.io为软件定义基础设施的开发者提供了一个平台,可以创建多个项目,开发基于软件的报文处理创新方案,以便于设计高吞吐量、低延时和有效利用资源的应用程序,并能够应用在多个平台上(x86、ARM和PowerPC)和部署在不同的环境中(裸机、虚拟机和容器)。

FD.io的一个关键项目是VPP(Vector Packet Processing:矢量报文处理)。VPP是高度模块化的项目,新开发的功能模块很容易被集成进VPP,而不影响VPP底层的代码框架。这就给了开发者很大的灵活性,可以创新不计其数的报文处理解决方案。
除了VPP,FD.io充分利用DPDK特性以支持额外的项目,包括NSH_SFC, Honeycomb 和ONE来加速网络功能虚拟化的数据面。此外,FD.io还与其他关键的开源项目进行集成,以支持网络功能虚拟化和软件定义网络。目前已经集成的开源项目包括:K8s、OpenStack、ONAP和OpenDaylight。
下图是FD.io的网络生态系统概览:
VPP简介
VPP到底是什么?一个软件路由器?一个虚拟交换机?一个虚拟网络功能?事实上,它包含所有这些,并且包含更多。VPP是一个模块化和可扩展的软件框架,用于创建网络数据面应用程序。更重要的是,VPP代码为现代通用处理器平台(x86、ARM、PowerPC等)而生,并把重点放在优化软件和硬件接口上,以便用于实时的网络输入输出操作和报文处理。
VPP充分利用通用处理器优化技术,包括矢量指令(例如Intel SSE, AVX)以及I/O和CPU缓存间的直接交互(例如 Intel DDIO),以达到最好的报文处理性能。利用这些优化技术的好处是:使用最少的CPU核心指令和时钟周期来处理每个报文。在最新的Intel Xeon-SP处理器上,可以达到Tbps的处理性能。
VPP架构
VPP是一个有效且灵活的数据面,它包括一系列按有向图组织的转发图形节点(graph node)和一个软件框架。该软件框架包含基本的数据结构、定时器、驱动程序、在图形节点间分配CPU时间片的调度器、性能调优工具,比如计数器和内建的报文跟踪功能。
VPP采用插件(plugin)架构,插件与直接内嵌于VPP框架中的模块一样被同等对待。原则上,插件是实现某一特定功能的转发图形节点,但也可以是一个驱动程序,或者另外的CLI。插件能被插入到VPP有向图的任意位置,从而有利于快速灵活地开发新功能。因此,插件架构使开发者能够充分利用现有模块快速开发出新功能。
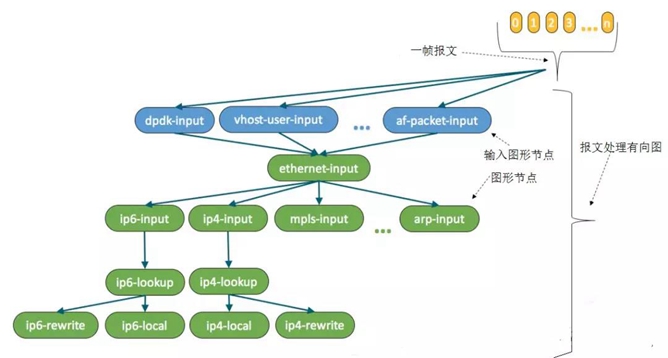
输入节点轮询(或中断驱动)接口的接收队列,获取批量报文。接着把这些报文按照下个节点功能组成一个矢量(vector)或者一帧(frame)。比如:输入节点收集所有IPv4的报文并把它们传递给ip4-input节点;输入节点收集所有IPv6的报文并把它们传递给ip6-input节点。当ip6-input节点被调度时,它取出这一帧报文,利用双循环(dual-loop) 或四循环(quad-loop)以及预取报文到CPU缓存技术处理报文,以达到最优性能。这能够通过减少缓存未命中数来有效利用CPU缓存。当ip6-input节点处理完当前帧的所有报文后,把报文传递到后续不同的节点。比如:如果某报文校验失败,就被传送到error-drop节点;正常报文被传送到ip6-lookup节点。一帧报文依次通过不同的图形节点,直到它们被interface-output节点发送出去。
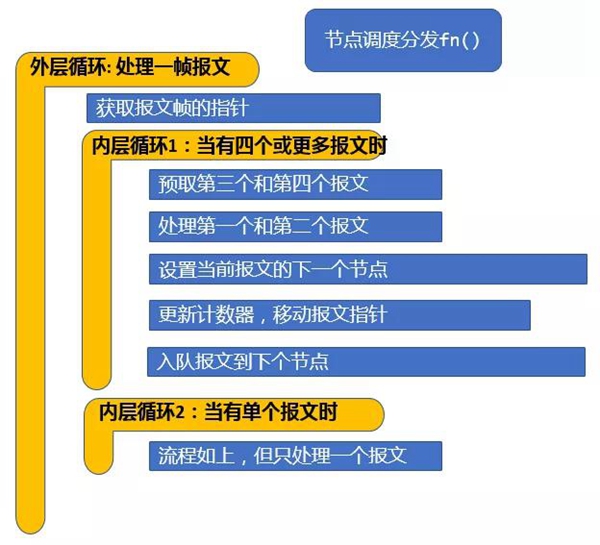
按照网络功能一次处理一帧报文,有几个好处:
- 从软件工程的角度看,每一个图形节点是独立和自治的。
- 从性能的角度看,主要的好处是可以优化CPU指令缓存(i-cache)的使用。当前帧的第一个报文加载当前节点的指令到指令缓存,当前帧的后续报文就可以“免费”使用指令缓存。这里,VPP充分利用了CPU的超标量结构,使报文内存加载和报文处理交织进行,达到更有效地利用CPU处理流水线。
- VPP也充分利用了CPU的预测执行功能来达到更好的性能。从预测重用报文间的转发对象(比如邻接表和路由查找表),以及预先加载报文内容到CPU的本地数据缓存(d-cache)供下一次循环使用,这些有效使用计算硬件的技术,使得VPP可以利用更细粒度的并行性。
VPP有向图处理的特性,使它成为一个松耦合、高度一致的软件架构。每一个图形节点利用一帧报文作为输入和输出的最小处理单位,这就提供了松耦合的特性。通用功能被组合到每个图形节点中,这就提供了高度一致的架构。
在有向图中的节点是可替代的。当这个特性和VPP支持动态加载插件节点相结合时,新功能能被快速开发,而不需要新建和编译一个定制的代码版本。
【参考资料】
1.https://wiki.fd.io/view/Main_Page
2.https://wiki.fd.io/view/VPP

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK