

Kubernetes 应用部署实战
source link: https://www.linuxprobe.com/kubernetes-distributed-application.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

伙计们,请搬好小板凳坐好,下面将是一段漫长的旅程,期望你能够乐在其中。
我将基于 Kubernetes[1] 部署一个分布式应用。我曾试图编写一个尽可能真实的应用,但由于时间和精力有限,最终砍掉了很多细节。
我将聚焦 Kubernetes 及其部署。
让我们开始吧。
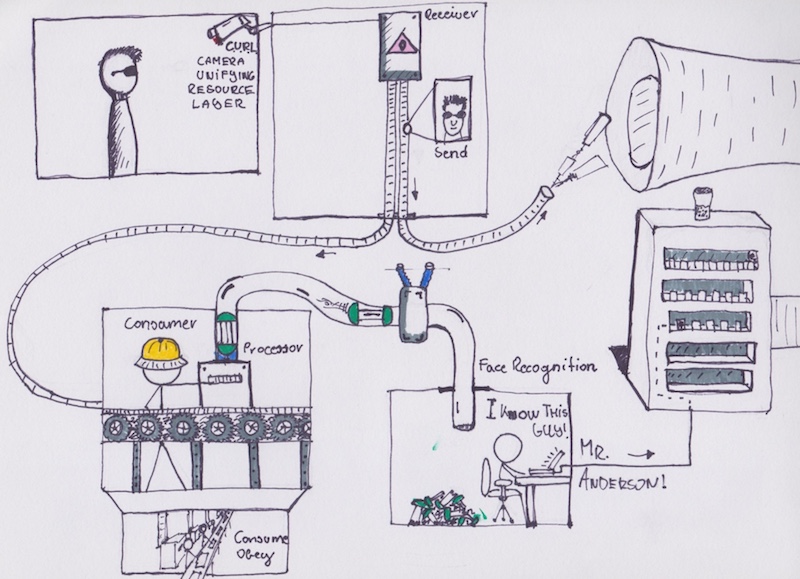
该应用本身由 6 个组件构成。代码可以从如下链接中找到:Kubenetes 集群示例[2]。
这是一个人脸识别服务,通过比较已知个人的图片,识别给定图片对应的个人。前端页面用表格形式简要的展示图片及对应的个人。具体而言,向 接收器[3] 发送请求,请求包含指向一个图片的链接。图片可以位于任何位置。接受器将图片地址存储到数据库 (MySQL) 中,然后向队列发送处理请求,请求中包含已保存图片的 ID。这里我们使用 NSQ[4] 建立队列。
图片处理[5] 服务一直监听处理请求队列,从中获取任务。处理过程包括如下几步:获取图片 ID,读取图片,通过 gRPC[6] 将图片路径发送至 Python 编写的 人脸识别[7] 后端。如果识别成功,后端给出图片对应个人的名字。图片处理器进而根据个人 ID 更新图片记录,将其标记为处理成功。如果识别不成功,图片被标记为待解决。如果图片识别过程中出现错误,图片被标记为失败。
标记为失败的图片可以通过计划任务等方式进行重试。
那么具体是如何工作的呢?我们深入探索一下。
接收器服务是整个流程的起点,通过如下形式的 API 接收请求:
curl -d '{"path":"/unknown_images/unknown0001.jpg"}' http://127.0.0.1:8000/image/post
此时,接收器将路径path存储到共享数据库集群中,该实体存储后将从数据库服务收到对应的 ID。本应用采用“实体对象Entity Object的唯一标识由持久层提供”的模型。获得实体 ID 后,接收器向 NSQ 发送消息,至此接收器的工作完成。
从这里开始变得有趣起来。图片处理器首次运行时会创建两个 Go 协程routine,具体为:
这是一个 NSQ 消费者,需要完成三项必需的任务。首先,监听队列中的消息。其次,当有新消息到达时,将对应的 ID 追加到一个线程安全的 ID 片段中,以供第二个协程处理。最后,告知第二个协程处理新任务,方法为 sync.Condition[8]。
该协程会处理指定 ID 片段,直到对应片段全部处理完成。当处理完一个片段后,该协程并不是在一个通道上睡眠等待,而是进入悬挂状态。对每个 ID,按如下步骤顺序处理:
- 与人脸识别服务建立 gRPC 连接,其中人脸识别服务会在人脸识别部分进行介绍
- 从数据库获取图片对应的实体
- 为 断路器[9] 准备两个函数
- 函数 1: 用于 RPC 方法调用的主函数
- 函数 2: 基于 ping 的断路器健康检查
- 调用函数 1 将图片路径发送至人脸识别服务,其中路径应该是人脸识别服务可以访问的,最好是共享的,例如 NFS
- 如果调用失败,将图片实体状态更新为 FAILEDPROCESSING
- 如果调用成功,返回值是一个图片的名字,对应数据库中的一个个人。通过联合 SQL 查询,获取对应个人的 ID
- 将数据库中的图片实体状态更新为 PROCESSED,更新图片被识别成的个人的 ID
这个服务可以复制多份同时运行。
即使对于一个复制资源几乎没有开销的系统,也会有意外的情况发生,例如网络故障或任何两个服务之间的通信存在问题等。我在 gRPC 调用中实现了一个简单的断路器,这十分有趣。
下面给出工作原理:
当出现 5 次不成功的服务调用时,断路器启动并阻断后续的调用请求。经过指定的时间后,它对服务进行健康检查并判断是否恢复。如果问题依然存在,等待时间会进一步增大。如果已经恢复,断路器停止对服务调用的阻断,允许请求流量通过。
前端只包含一个极其简单的表格视图,通过 Go 自身的 html/模板显示一系列图片。
人脸识别是整个识别的关键点。仅因为追求灵活性,我将这个服务设计为基于 gRPC 的服务。最初我使用 Go 编写,但后续发现基于 Python 的实现更加适合。事实上,不算 gRPC 部分的代码,人脸识别部分仅有 7 行代码。我使用的人脸识别[10]库极为出色,它包含 OpenCV 的全部 C 绑定。维护 API 标准意味着只要标准本身不变,实现可以任意改变。
注意:我曾经试图使用 GoCV[11],这是一个极好的 Go 库,但欠缺所需的 C 绑定。推荐马上了解一下这个库,它会让你大吃一惊,例如编写若干行代码即可实现实时摄像处理。
这个 Python 库的工作方式本质上很简单。准备一些你认识的人的图片,把信息记录下来。对于我而言,我有一个图片文件夹,包含若干图片,名称分别为 hannibal_1.jpg、 hannibal_2.jpg、 gergely_1.jpg、 john_doe.jpg。在数据库中,我使用两个表记录信息,分别为 person、 person_images,具体如下:
+----+----------+ | id | name | +----+----------+ | 1 | Gergely | | 2 | John Doe | | 3 | Hannibal | +----+----------+ +----+----------------+-----------+ | id | image_name | person_id | +----+----------------+-----------+ | 1 | hannibal_1.jpg | 3 | | 2 | hannibal_2.jpg | 3 | +----+----------------+-----------+
人脸识别库识别出未知图片后,返回图片的名字。我们接着使用类似下面的联合查询找到对应的个人。
select person.name, person.id from person inner join person_images as pi on person.id = pi.person_id where image_name = 'hannibal_2.jpg';
gRPC 调用返回的个人 ID 用于更新图片的 person 列。
NSQ 是 Go 编写的小规模队列,可扩展且占用系统内存较少。NSQ 包含一个查询服务,用于消费者接收消息;包含一个守护进程,用于发送消息。
在 NSQ 的设计理念中,消息发送程序应该与守护进程在同一台主机上,故发送程序仅需发送至 localhost。但守护进程与查询服务相连接,这使其构成了全局队列。
这意味着有多少 NSQ 守护进程就有多少对应的发送程序。但由于其资源消耗极小,不会影响主程序的资源使用。
为了尽可能增加灵活性以及使用 Kubernetes 的 ConfigSet 特性,我在开发过程中使用 .env 文件记录配置信息,例如数据库服务的地址以及 NSQ 的查询地址。在生产环境或 Kubernetes 环境中,我将使用环境变量属性配置。
这就是待部署应用的全部架构信息。应用的各个组件都是可变更的,他们之间仅通过数据库、消息队列和 gRPC 进行耦合。考虑到更新机制的原理,这是部署分布式应用所必须的;在部署部分我会继续分析。
Kubernetes 是什么?
这里我会提到一些基础知识,但不会深入细节,细节可以用一本书的篇幅描述,例如 Kubernetes 构建与运行[12]。另外,如果你愿意挑战自己,可以查看官方文档:Kubernetes 文档[13]。
Kubernetes 是容器化服务及应用的管理器。它易于扩展,可以管理大量容器;更重要的是,可以通过基于 yaml 的模板文件高度灵活地进行配置。人们经常把 Kubernetes 比作 Docker Swarm,但 Kubernetes 的功能不仅仅如此。例如,Kubernetes 不关心底层容器实现,你可以使用 LXC 与 Kubernetes 的组合,效果与使用 Docker 一样好。Kubernetes 在管理容器的基础上,可以管理已部署的服务或应用集群。如何操作呢?让我们概览一下用于构成 Kubernetes 的模块。
在 Kubernetes 中,你给出期望的应用状态,Kubernetes 会尽其所能达到对应的状态。状态可以是已部署、已暂停,有 2 个副本等,以此类推。
Kubernetes 使用标签和注释标记组件,包括服务、部署、副本组、守护进程组等在内的全部组件都被标记。考虑如下场景,为了识别 pod 与应用的对应关系,使用 app: myapp 标签。假设应用已部署 2 个容器,如果你移除其中一个容器的 app 标签,Kubernetes 只能识别到一个容器(隶属于应用),进而启动一个新的具有 myapp 标签的实例。
要使用 Kubernetes,需要先搭建一个 Kubernetes 集群。搭建 Kubernetes 集群可能是一个痛苦的经历,但所幸有工具可以帮助我们。Minikube 为我们在本地搭建一个单节点集群。AWS 的一个 beta 服务工作方式类似于 Kubernetes 集群,你只需请求节点并定义你的部署即可。Kubernetes 集群组件的文档如下:Kubernetes 集群组件[14]。
节点node是工作单位,形式可以是虚拟机、物理机,也可以是各种类型的云主机。
Pod 是本地容器逻辑上组成的集合,即一个 Pod 中可能包含若干个容器。Pod 创建后具有自己的 DNS 和虚拟 IP,这样 Kubernetes 可以对到达流量进行负载均衡。你几乎不需要直接和容器打交道;即使是调试的时候,例如查看日志,你通常调用 kubectl logs deployment/your-app -f 查看部署日志,而不是使用 -c container_name 查看具体某个容器的日志。-f 参数表示从日志尾部进行流式输出。
在 Kubernetes 中创建任何类型的资源时,后台使用一个部署deployment组件,它指定了资源的期望状态。使用部署对象,你可以将 Pod 或服务变更为另外的状态,也可以更新应用或上线新版本应用。你一般不会直接操作副本组 (后续会描述),而是通过部署对象创建并管理。
默认情况下,Pod 会获取一个 IP 地址。但考虑到 Pod 是 Kubernetes 中的易失性组件,我们需要更加持久的组件。不论是队列,MySQL、内部 API 或前端,都需要长期运行并使用保持不变的 IP 或更好的 DNS 记录。
为解决这个问题,Kubernetes 提供了服务service组件,可以定义访问模式,支持的模式包括负载均衡、简单 IP 或内部 DNS。
Kubernetes 如何获知服务运行正常呢?你可以配置健康性检查和可用性检查。健康性检查是指检查容器是否处于运行状态,但容器处于运行状态并不意味着服务运行正常。对此,你应该使用可用性检查,即请求应用的一个特别接口endpoint。
由于服务非常重要,推荐你找时间阅读以下文档:服务[15]。严肃的说,需要阅读的东西很多,有 24 页 A4 纸的篇幅,涉及网络、服务及自动发现。这也有助于你决定是否真的打算在生产环境中使用 Kubernetes。
在 Kubernetes 集群中创建服务后,该服务会从名为 kube-proxy 和 kube-dns 的特殊 Kubernetes 部署中获取一个 DNS 记录。它们两个用于提供集群内的服务发现。如果你有一个正在运行的 MySQL 服务并配置 clusterIP: no,那么集群内部任何人都可以通过 mysql.default.svc.cluster.local 访问该服务,其中:
- mysql – 服务的名称
- default – 命名空间的名称
- svc – 对应服务分类
- cluster.local – 本地集群的域名
可以使用自定义设置更改本地集群的域名。如果想让服务可以从集群外访问,需要使用 DNS 服务,并使用例如 Nginx 将 IP 地址绑定至记录。服务对应的对外 IP 地址可以使用如下命令查询:
- 节点端口方式 – kubectl get -o jsonpath="{.spec.ports[0].nodePort}" services mysql
- 负载均衡方式 – kubectl get -o jsonpath="{.spec.ports[0].LoadBalancer}" services mysql
类似 Docker Compose、TerraForm 或其它的服务管理工具,Kubernetes 也提供了基础设施描述模板。这意味着,你几乎不用手动操作。
以 Nginx 部署为例,查看下面的 yaml 模板:
apiVersion: apps/v1
kind: Deployment #(1)
metadata: #(2)
name: nginx-deployment
labels: #(3)
app: nginx
spec: #(4)
replicas: 3 #(5)
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers: #(6)
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
在这个示例部署中,我们做了如下操作:
- (1) 使用 kind 关键字定义模板类型
- (2) 使用 metadata 关键字,增加该部署的识别信息
- (3) 使用 labels 标记每个需要创建的资源
- (4) 然后使用 spec 关键字描述所需的状态
- (5) nginx 应用需要 3 个副本
- (6) Pod 中容器的模板定义部分
- 容器名称为 nginx
- 容器模板为 nginx:1.7.9 (本例使用 Docker 镜像)
副本组ReplicaSet是一个底层的副本管理器,用于保证运行正确数目的应用副本。相比而言,部署是更高层级的操作,应该用于管理副本组。除非你遇到特殊的情况,需要控制副本的特性,否则你几乎不需要直接操作副本组。
上面提到 Kubernetes 始终使用标签,还有印象吗?守护进程组DaemonSet是一个控制器,用于确保守护进程化的应用一直运行在具有特定标签的节点中。
例如,你将所有节点增加 logger 或 mission_critical 的标签,以便运行日志 / 审计服务的守护进程。接着,你创建一个守护进程组并使用 logger 或 mission_critical 节点选择器。Kubernetes 会查找具有该标签的节点,确保守护进程的实例一直运行在这些节点中。因而,节点中运行的所有进程都可以在节点内访问对应的守护进程。
以我的应用为例,NSQ 守护进程可以用守护进程组实现。具体而言,将对应节点增加 recevier 标签,创建一个守护进程组并配置 receiver 应用选择器,这样这些节点上就会一直运行接收者组件。
守护进程组具有副本组的全部优势,可扩展且由 Kubernetes 管理,意味着 Kubernetes 管理其全生命周期的事件,确保持续运行,即使出现故障,也会立即替换。
在 Kubernetes 中,扩展是稀松平常的事情。副本组负责 Pod 运行的实例数目。就像你在 nginx 部署那个示例中看到的那样,对应设置项 replicas:3。我们可以按应用所需,让 Kubernetes 运行多份应用副本。
当然,设置项有很多。你可以指定让多个副本运行在不同的节点上,也可以指定各种不同的应用启动等待时间。想要在这方面了解更多,可以阅读 水平扩展[16] 和 Kubernetes 中的交互式扩展[17];当然 副本组[18] 的细节对你也有帮助,毕竟 Kubernetes 中的扩展功能都来自于该模块。
Kubernetes 是容器编排的便捷工具,工作单元为 Pod,具有分层架构。最顶层是部署,用于操作其它资源,具有高度可配置性。对于你的每个命令调用,Kubernetes 提供了对应的 API,故理论上你可以编写自己的代码,向 Kubernetes API 发送数据,得到与 kubectl 命令同样的效果。
截至目前,Kubernetes 原生支持所有主流云服务供应商,而且完全开源。如果你愿意,可以贡献代码;如果你希望对工作原理有深入了解,可以查阅代码:GitHub 上的 Kubernetes 项目[19]。
接下来我会使用 Minikube[20] 这款本地 Kubernetes 集群模拟器。它并不擅长模拟多节点集群,但可以很容易地给你提供本地学习环境,让你开始探索,这很棒。Minikube 基于可高度调优的虚拟机,由 VirtualBox 类似的虚拟化工具提供。
我用到的全部 Kubernetes 模板文件可以在这里找到:Kubernetes 文件[21]。
注意:在你后续测试可扩展性时,会发现副本一直处于 Pending 状态,这是因为 minikube 集群中只有一个节点,不应该允许多副本运行在同一个节点上,否则明显只是耗尽了可用资源。使用如下命令可以查看可用资源:
kubectl get nodes -o yaml
Kubernetes 支持大多数现有的容器技术。我这里使用 Docker。每一个构建的服务容器,对应代码库中的一个 Dockerfile 文件。我推荐你仔细阅读它们,其中大多数都比较简单。对于 Go 服务,我采用了最近引入的多步构建的方式。Go 服务基于 Alpine Linux 镜像创建。人脸识别程序使用 Python、NSQ 和 MySQL 使用对应的容器。
Kubernetes 使用命名空间。如果你不额外指定命名空间,Kubernetes 会使用 default 命名空间。为避免污染默认命名空间,我会一直指定命名空间,具体操作如下:
❯ kubectl config set-context kube-face-cluster --namespace=face Context "kube-face-cluster" created.
创建上下文之后,应马上启用:
❯ kubectl config use-context kube-face-cluster Switched to context "kube-face-cluster".
此后,所有 kubectl 命令都会使用 face 命名空间。
(LCTT 译注:作者后续并没有使用 face 命名空间,模板文件中的命名空间仍为 default,可能 face 命名空间用于开发环境。如果希望使用 face 命令空间,需要将内部 DNS 地址中的 default 改成 face;如果只是测试,可以不执行这两条命令。)
Pods 和 服务概览:
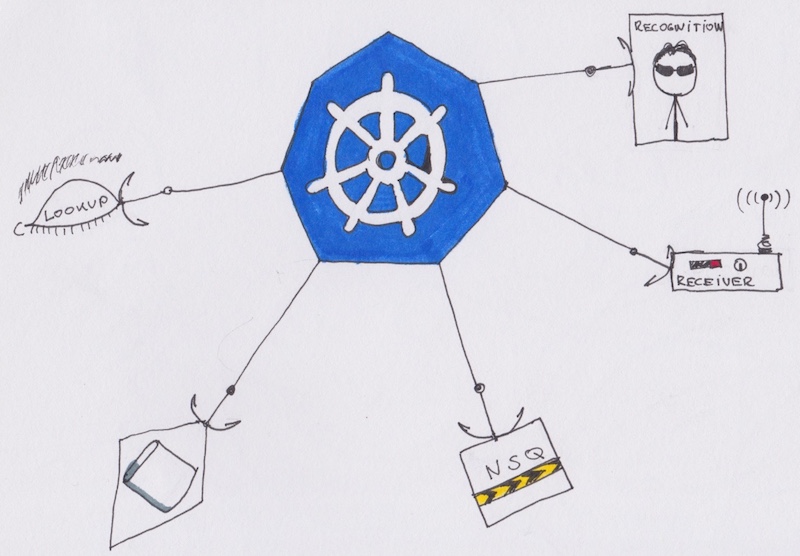
第一个要部署的服务是数据库。
按照 Kubernetes 的示例 Kubenetes MySQL[22] 进行部署,即可以满足我的需求。注意:示例配置文件的 MYSQL_PASSWORD 字段使用了明文密码,我将使用 Kubernetes Secrets[23] 对象以提高安全性。
我创建了一个 Secret 对象,对应的本地 yaml 文件如下:
apiVersion: v1 kind: Secret metadata: name: kube-face-secret type: Opaque data: mysql_password: base64codehere mysql_userpassword: base64codehere
其中 base64 编码通过如下命令生成:
echo -n "ubersecurepassword" | base64 echo -n "root:ubersecurepassword" | base64
(LCTT 译注:secret yaml 文件中的 data 应该有两条,一条对应 mysql_password,仅包含密码;另一条对应 mysql_userpassword,包含用户和密码。后文会用到 mysql_userpassword,但没有提及相应的生成)
我的部署 yaml 对应部分如下:
...
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: kube-face-secret
key: mysql_password
...
另外值得一提的是,我使用卷将数据库持久化,卷对应的定义如下:
...
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
...
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
...
其中 presistentVolumeClain 是关键,告知 Kubernetes 当前资源需要持久化存储。持久化存储的提供方式对用户透明。类似 Pods,如果想了解更多细节,参考文档:Kubernetes 持久化存储[24]。
(LCTT 译注:使用 presistentVolumeClain 之前需要创建 presistentVolume,对于单节点可以使用本地存储,对于多节点需要使用共享存储,因为 Pod 可以能调度到任何一个节点)
使用如下命令部署 MySQL 服务:
kubectl apply -f mysql.yaml
这里比较一下 create 和 apply。apply 是一种宣告式declarative的对象配置命令,而 create 是命令式imperative的命令。当下我们需要知道的是,create 通常对应一项任务,例如运行某个组件或创建一个部署;相比而言,当我们使用 apply 的时候,用户并没有指定具体操作,Kubernetes 会根据集群目前的状态定义需要执行的操作。故如果不存在名为 mysql 的服务,当我执行 apply -f mysql.yaml 时,Kubernetes 会创建该服务。如果再次执行这个命令,Kubernetes 会忽略该命令。但如果我再次运行 create,Kubernetes 会报错,告知服务已经创建。
想了解更多信息,请阅读如下文档:Kubernetes 对象管理[25],命令式配置[26]和宣告式配置[27]。
运行如下命令查看执行进度信息:
# 描述完整信息 kubectl describe deployment mysql # 仅描述 Pods 信息 kubectl get pods -l app=mysql
(第一个命令)输出示例如下:
... Type Status Reason ---- ------ ------ Available True MinimumReplicasAvailable Progressing True NewReplicaSetAvailable OldReplicaSets: <none> NewReplicaSet: mysql-55cd6b9f47 (1/1 replicas created) ...
对于 get pods 命令,输出示例如下:
NAME READY STATUS RESTARTS AGE mysql-78dbbd9c49-k6sdv 1/1 Running 0 18s
可以使用下面的命令测试数据库实例:
kubectl run -it --rm --image=mysql:5.6 --restart=Never mysql-client -- mysql -h mysql -pyourpasswordhere
特别提醒:如果你在这里修改了密码,重新 apply 你的 yaml 文件并不能更新容器。因为数据库是持久化的,密码并不会改变。你需要先使用 kubectl delete -f mysql.yaml 命令删除整个部署。
运行 show databases 后,应该可以看到如下信息:
If you don't see a command prompt, try pressing enter. mysql> mysql> mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | kube | | mysql | | performance_schema | +--------------------+ 4 rows in set (0.00 sec) mysql> exit Bye
你会注意到,我还将一个数据库初始化 SQL[28] 文件挂载到容器中,MySQL 容器会自动运行该文件,导入我将用到的部分数据和模式。
对应的卷定义如下:
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
- name: bootstrap-script
mountPath: /docker-entrypoint-initdb.d/database_setup.sql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
- name: bootstrap-script
hostPath:
path: /Users/hannibal/golang/src/github.com/Skarlso/kube-cluster-sample/database_setup.sql
type: File
(LCTT 译注:数据库初始化脚本需要改成对应的路径,如果是多节点,需要是共享存储中的路径。另外,作者给的 sql 文件似乎有误,person_images 表中的 person_id 列数字都小 1,作者默认 id 从 0 开始,但应该是从 1 开始)
运行如下命令查看引导脚本是否正确执行:
~/golang/src/github.com/Skarlso/kube-cluster-sample/kube_files master* ❯ kubectl run -it --rm --image=mysql:5.6 --restart=Never mysql-client -- mysql -h mysql -uroot -pyourpasswordhere kube If you don't see a command prompt, try pressing enter. mysql> show tables; +----------------+ | Tables_in_kube | +----------------+ | images | | person | | person_images | +----------------+ 3 rows in set (0.00 sec) mysql>
(LCTT 译注:上述代码块中的第一行是作者执行命令所在路径,执行第二行的命令无需在该目录中进行)
上述操作完成了数据库服务的初始化。使用如下命令可以查看服务日志:
kubectl logs deployment/mysql -f
NSQ 查询将以内部服务的形式运行。由于不需要外部访问,这里使用 clusterIP: None 在 Kubernetes 中将其设置为无头服务headless service,意味着该服务不使用负载均衡模式,也不使用单独的服务 IP。DNS 将基于服务选择器selectors。
我们的 NSQ 查询服务对应的选择器为:
selector:
matchLabels:
app: nsqlookup
那么,内部 DNS 对应的实体类似于:nsqlookup.default.svc.cluster.local。
无头服务的更多细节,可以参考:无头服务[29]。
NSQ 服务与 MySQL 服务大同小异,只需要少许修改即可。如前所述,我将使用 NSQ 原生的 Docker 镜像,名称为 nsqio/nsq。镜像包含了全部的 nsq 命令,故 nsqd 也将使用该镜像,只是使用的命令不同。对于 nsqlookupd,命令如下:
command: ["/nsqlookupd"] args: ["--broadcast-address=nsqlookup.default.svc.cluster.local"]
你可能会疑惑,--broadcast-address 参数是做什么用的?默认情况下,nsqlookup 使用容器的主机名作为广播地址;这意味着,当用户运行回调时,回调试图访问的地址类似于 http://nsqlookup-234kf-asdf:4161/lookup?topics=image,但这显然不是我们期望的。将广播地址设置为内部 DNS 后,回调地址将是 http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images,这正是我们期望的。
NSQ 查询还需要转发两个端口,一个用于广播,另一个用于 nsqd 守护进程的回调。在 Dockerfile 中暴露相应端口,在 Kubernetes 模板中使用它们,类似如下:
容器模板:
ports:
- containerPort: 4160
hostPort: 4160
- containerPort: 4161
hostPort: 4161
服务模板:
spec:
ports:
- name: main
protocol: TCP
port: 4160
targetPort: 4160
- name: secondary
protocol: TCP
port: 4161
targetPort: 4161
端口名称是必须的,Kubernetes 基于名称进行区分。(LCTT 译注:端口名更新为作者 GitHub 对应文件中的名称)
像之前那样,使用如下命令创建服务:
kubectl apply -f nsqlookup.yaml
nsqlookupd 部分到此结束。截至目前,我们已经准备好两个主要的组件。
这部分略微复杂。接收器需要完成三项工作:
- 创建一些部署
- 创建 nsq 守护进程
- 将本服务对外公开
部署
第一个要创建的部署是接收器本身,容器镜像为 skarlso/kube-receiver-alpine。
NSQ 守护进程
接收器需要使用 NSQ 守护进程。如前所述,接收器在其内部运行一个 NSQ,这样与 nsq 的通信可以在本地进行,无需通过网络。为了让接收器可以这样操作,NSQ 需要与接收器部署在同一个节点上。
NSQ 守护进程也需要一些调整的参数配置:
ports:
- containerPort: 4150
hostPort: 4150
- containerPort: 4151
hostPort: 4151
env:
- name: NSQLOOKUP_ADDRESS
value: nsqlookup.default.svc.cluster.local
- name: NSQ_BROADCAST_ADDRESS
value: nsqd.default.svc.cluster.local
command: ["/nsqd"]
args: ["--lookupd-tcp-address=$(NSQLOOKUP_ADDRESS):4160", "--broadcast-address=$(NSQ_BROADCAST_ADDRESS)"]
其中我们配置了 lookup-tcp-address 和 broadcast-address 参数。前者是 nslookup 服务的 DNS 地址,后者用于回调,就像 nsqlookupd 配置中那样。
对外公开
下面即将创建第一个对外公开的服务。有两种方式可供选择。考虑到该 API 负载较高,可以使用负载均衡的方式。另外,如果希望将其部署到生产环境中的任选节点,也应该使用负载均衡方式。
但由于我使用的本地集群只有一个节点,那么使用 NodePort 的方式就足够了。NodePort 方式将服务暴露在对应节点的固定端口上。如果未指定端口,将从 30000-32767 数字范围内随机选其一个。也可以指定端口,可以在模板文件中使用 nodePort 设置即可。可以通过 <NodeIP>:<NodePort> 访问该服务。如果使用多个节点,负载均衡可以将多个 IP 合并为一个 IP。
更多信息,请参考文档:服务发布[30]。
结合上面的信息,我们定义了接收器服务,对应的模板如下:
apiVersion: v1
kind: Service
metadata:
name: receiver-service
spec:
ports:
- protocol: TCP
port: 8000
targetPort: 8000
selector:
app: receiver
type: NodePort
如果希望固定使用 8000 端口,需要增加 nodePort 配置,具体如下:
apiVersion: v1
kind: Service
metadata:
name: receiver-service
spec:
ports:
- protocol: TCP
port: 8000
targetPort: 8000
selector:
app: receiver
type: NodePort
nodePort: 8000
(LCTT 译注:虽然作者没有写,但我们应该知道需要运行的部署命令 kubectl apply -f receiver.yaml。)
图片处理器用于将图片传送至识别组件。它需要访问 nslookupd、 mysql 以及后续部署的人脸识别服务的 gRPC 接口。事实上,这是一个无聊的服务,甚至其实并不是服务(LCTT 译注:第一个服务是指在整个架构中,图片处理器作为一个服务;第二个服务是指 Kubernetes 服务)。它并需要对外暴露端口,这是第一个只包含部署的组件。长话短说,下面是完整的模板:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: image-processor-deployment
spec:
selector:
matchLabels:
app: image-processor
replicas: 1
template:
metadata:
labels:
app: image-processor
spec:
containers:
- name: image-processor
image: skarlso/kube-processor-alpine:latest
env:
- name: MYSQL_CONNECTION
value: "mysql.default.svc.cluster.local"
- name: MYSQL_USERPASSWORD
valueFrom:
secretKeyRef:
name: kube-face-secret
key: mysql_userpassword
- name: MYSQL_PORT
# TIL: If this is 3306 without " kubectl throws an error.
value: "3306"
- name: MYSQL_DBNAME
value: kube
- name: NSQ_LOOKUP_ADDRESS
value: "nsqlookup.default.svc.cluster.local:4161"
- name: GRPC_ADDRESS
value: "face-recog.default.svc.cluster.local:50051"
文件中唯一需要提到的是用于配置应用的多个环境变量属性,主要关注 nsqlookupd 地址 和 gRPC 地址。
运行如下命令完成部署:
kubectl apply -f image_processor.yaml
人脸识别服务的确包含一个 Kubernetes 服务,具体而言是一个比较简单、仅供图片处理器使用的服务。模板如下:
apiVersion: v1
kind: Service
metadata:
name: face-recog
spec:
ports:
- protocol: TCP
port: 50051
targetPort: 50051
selector:
app: face-recog
clusterIP: None
更有趣的是,该服务涉及两个卷,分别为 known_people 和 unknown_people。你能猜到卷中包含什么内容吗?对,是图片。known_people 卷包含所有新图片,接收器收到图片后将图片发送至该卷对应的路径,即挂载点。在本例中,挂载点为 /unknown_people,人脸识别服务需要能够访问该路径。
对于 Kubernetes 和 Docker 而言,这很容易。卷可以使用挂载的 S3 或 某种 nfs,也可以是宿主机到虚拟机的本地挂载。可选方式有很多 (至少有一打那么多)。为简洁起见,我将使用本地挂载方式。
挂载卷分为两步。第一步,需要在 Dockerfile 中指定卷:
VOLUME [ "/unknown_people", "/known_people" ]
第二步,就像之前为 MySQL Pod 挂载卷那样,需要在 Kubernetes 模板中配置;相比而言,这里使用 hostPath,而不是 MySQL 例子中的 PersistentVolumeClaim:
volumeMounts:
- name: known-people-storage
mountPath: /known_people
- name: unknown-people-storage
mountPath: /unknown_people
volumes:
- name: known-people-storage
hostPath:
path: /Users/hannibal/Temp/known_people
type: Directory
- name: unknown-people-storage
hostPath:
path: /Users/hannibal/Temp/
type: Directory
(LCTT 译注:对于多节点模式,由于人脸识别服务和接收器服务可能不在一个节点上,故需要使用共享存储而不是节点本地存储。另外,出于 Python 代码的逻辑,推荐保持两个文件夹的嵌套结构,即 known_people 作为子目录。)
我们还需要为 known_people 文件夹做配置设置,用于人脸识别程序。当然,使用环境变量属性可以完成该设置:
env:
- name: KNOWN_PEOPLE
value: "/known_people"
Python 代码按如下方式搜索图片:
known_people = os.getenv('KNOWN_PEOPLE', 'known_people')
print("Known people images location is: %s" % known_people)
images = self.image_files_in_folder(known_people)
其中 image_files_in_folder 函数定义如下:
def image_files_in_folder(self, folder):
return [os.path.join(folder, f) for f in os.listdir(folder) if re.match(r'.*\.(jpg|jpeg|png)', f, flags=re.I)]
看起来不错。
如果接收器现在收到一个类似下面的请求(接收器会后续将其发送出去):
curl -d '{"path":"/unknown_people/unknown220.jpg"}' http://192.168.99.100:30251/image/post
图像处理器会在 /unknown_people 目录搜索名为 unknown220.jpg 的图片,接着在 known_folder 文件中找到 unknown220.jpg 对应个人的图片,最后返回匹配图片的名称。
查看日志,大致信息如下:
# 接收器
❯ curl -d '{"path":"/unknown_people/unknown219.jpg"}' http://192.168.99.100:30251/image/post
got path: {Path:/unknown_people/unknown219.jpg}
image saved with id: 4
image sent to nsq
# 图片处理器
2018/03/26 18:11:21 INF 1 [images/ch] querying nsqlookupd http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images
2018/03/26 18:11:59 Got a message: 4
2018/03/26 18:11:59 Processing image id: 4
2018/03/26 18:12:00 got person: Hannibal
2018/03/26 18:12:00 updating record with person id
2018/03/26 18:12:00 done
我们已经使用 Kubernetes 部署了应用正常工作所需的全部服务。
更进一步,可以使用简易的 Web 应用更好的显示数据库中的信息。这也是一个对外公开的服务,使用的参数可以参考接收器。
部署后效果如下:

到目前为止我们做了哪些操作呢?我一直在部署服务,用到的命令汇总如下:
kubectl apply -f mysql.yaml kubectl apply -f nsqlookup.yaml kubectl apply -f receiver.yaml kubectl apply -f image_processor.yaml kubectl apply -f face_recognition.yaml kubectl apply -f frontend.yaml
命令顺序可以打乱,因为除了图片处理器的 NSQ 消费者外的应用在启动时并不会建立连接,而且图片处理器的 NSQ 消费者会不断重试。
使用 kubectl get pods 查询正在运行的 Pods,示例如下:
❯ kubectl get pods NAME READY STATUS RESTARTS AGE face-recog-6bf449c6f-qg5tr 1/1 Running 0 1m image-processor-deployment-6467468c9d-cvx6m 1/1 Running 0 31s mysql-7d667c75f4-bwghw 1/1 Running 0 36s nsqd-584954c44c-299dz 1/1 Running 0 26s nsqlookup-7f5bdfcb87-jkdl7 1/1 Running 0 11s receiver-deployment-5cb4797598-sf5ds 1/1 Running 0 26s
运行 minikube service list:
❯ minikube service list |-------------|----------------------|-----------------------------| | NAMESPACE | NAME | URL | |-------------|----------------------|-----------------------------| | default | face-recog | No node port | | default | kubernetes | No node port | | default | mysql | No node port | | default | nsqd | No node port | | default | nsqlookup | No node port | | default | receiver-service | http://192.168.99.100:30251 | | kube-system | kube-dns | No node port | | kube-system | kubernetes-dashboard | http://192.168.99.100:30000 | |-------------|----------------------|-----------------------------|
滚动更新Rolling Update过程中会发生什么呢?
在软件开发过程中,需要变更应用的部分组件是常有的事情。如果我希望在不影响其它组件的情况下变更一个组件,我们的集群会发生什么变化呢?我们还需要最大程度的保持向后兼容性,以免影响用户体验。谢天谢地,Kubernetes 可以帮我们做到这些。
目前的 API 一次只能处理一个图片,不能批量处理,对此我并不满意。
目前,我们使用下面的代码段处理单个图片的情形:
// PostImage 对图片提交做出响应,将图片信息保存到数据库中
// 并将该信息发送给 NSQ 以供后续处理使用
func PostImage(w http.ResponseWriter, r *http.Request) {
...
}
func main() {
router := mux.NewRouter()
router.HandleFunc("/image/post", PostImage).Methods("POST")
log.Fatal(http.ListenAndServe(":8000", router))
}
我们有两种选择。一种是增加新接口 /images/post 给用户使用;另一种是在原接口基础上修改。
新版客户端有回退特性,在新接口不可用时回退使用旧接口。但旧版客户端没有这个特性,故我们不能马上修改代码逻辑。考虑如下场景,你有 90 台服务器,计划慢慢执行滚动更新,依次对各台服务器进行业务更新。如果一台服务需要大约 1 分钟更新业务,那么整体更新完成需要大约 1 个半小时的时间(不考虑并行更新的情形)。
更新过程中,一些服务器运行新代码,一些服务器运行旧代码。用户请求被负载均衡到各个节点,你无法控制请求到达哪台服务器。如果客户端的新接口请求被调度到运行旧代码的服务器,请求会失败;客户端可能会回退使用旧接口,(但由于我们已经修改旧接口,本质上仍然是调用新接口),故除非请求刚好到达到运行新代码的服务器,否则一直都会失败。这里我们假设不使用粘性会话sticky sessions。
而且,一旦所有服务器更新完毕,旧版客户端不再能够使用你的服务。
这里,你可能会说你并不需要保留旧代码;某些情况下,确实如此。因此,我们打算直接修改旧代码,让其通过少量参数调用新代码。这样操作操作相当于移除了旧代码。当所有客户端迁移完毕后,这部分代码也可以安全地删除。
让我们添加新的路由方法:
...
router.HandleFunc("/images/post", PostImages).Methods("POST")
...
更新旧的路由方法,使其调用新的路由方法,修改部分如下:
// PostImage 对图片提交做出响应,将图片信息保存到数据库中
// 并将该信息发送给 NSQ 以供后续处理使用
func PostImage(w http.ResponseWriter, r *http.Request) {
var p Path
err := json.NewDecoder(r.Body).Decode(&p)
if err != nil {
fmt.Fprintf(w, "got error while decoding body: %s", err)
return
}
fmt.Fprintf(w, "got path: %+v\n", p)
var ps Paths
paths := make([]Path, 0)
paths = append(paths, p)
ps.Paths = paths
var pathsJSON bytes.Buffer
err = json.NewEncoder(&pathsJSON).Encode(ps)
if err != nil {
fmt.Fprintf(w, "failed to encode paths: %s", err)
return
}
r.Body = ioutil.NopCloser(&pathsJSON)
r.ContentLength = int64(pathsJSON.Len())
PostImages(w, r)
}
当然,方法名可能容易混淆,但你应该能够理解我想表达的意思。我将请求中的单个路径封装成新方法所需格式,然后将其作为请求发送给新接口处理。仅此而已。在 滚动更新批量图片的 PR[31] 中可以找到更多的修改方式。
至此,我们使用两种方法调用接收器:
# 单路径模式
curl -d '{"path":"unknown4456.jpg"}' http://127.0.0.1:8000/image/post
# 多路径模式
curl -d '{"paths":[{"path":"unknown4456.jpg"}]}' http://127.0.0.1:8000/images/post
这里用到的客户端是 curl。一般而言,如果客户端本身是一个服务,我会做一些修改,在新接口返回 404 时继续尝试旧接口。
为了简洁,我不打算为 NSQ 和其它组件增加批量图片处理的能力。这些组件仍然是一次处理一个图片。这部分修改将留给你作为扩展内容。 :)
为实现滚动更新,我首先需要为接收器服务创建一个新的镜像。新镜像使用新标签,告诉大家版本号为 v1.1。
docker build -t skarlso/kube-receiver-alpine:v1.1 .
新镜像创建后,我们可以开始滚动更新了。
在 Kubernetes 中,可以使用多种方式完成滚动更新。
手动更新
不妨假设在我配置文件中使用的容器版本为 v1.0,那么实现滚动更新只需运行如下命令:
kubectl rolling-update receiver --image:skarlso/kube-receiver-alpine:v1.1
如果滚动更新过程中出现问题,我们总是可以回滚:
kubectl rolling-update receiver --rollback
容器将回滚到使用上一个版本镜像,操作简捷无烦恼。
应用新的配置文件
手动更新的不足在于无法版本管理。
试想下面的场景。你使用手工更新的方式对若干个服务器进行滚动升级,但其它人并不知道这件事。之后,另外一个人修改了模板文件并将其应用到集群中,更新了全部服务器;更新过程中,突然发现服务不可用了。
长话短说,由于模板无法识别已经手动更新的服务器,这些服务器会按模板变更成错误的状态。这种做法很危险,千万不要这样做。
推荐的做法是,使用新版本信息更新模板文件,然后使用 apply 命令应用模板文件。
对于滚动扩展,Kubernetes 推荐通过部署结合副本组完成。但这意味着待滚动更新的应用至少有 2 个副本,否则无法完成 (除非将 maxUnavailable 设置为 1)。我在模板文件中增加了副本数量、设置了接收器容器的新镜像版本。
replicas: 2
...
spec:
containers:
- name: receiver
image: skarlso/kube-receiver-alpine:v1.1
...
更新过程中,你会看到如下信息:
❯ kubectl rollout status deployment/receiver-deployment Waiting for rollout to finish: 1 out of 2 new replicas have been updated...
通过在模板中增加 strategy 段,你可以增加更多的滚动扩展配置:
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
关于滚动更新的更多信息,可以参考如下文档:部署的滚动更新[32],部署的更新[33], 部署的管理[34] 和 使用副本控制器完成滚动更新[35]等。
MINIKUBE 用户需要注意:由于我们使用单个主机上使用单节点配置,应用只有 1 份副本,故需要将 maxUnavailable 设置为 1。否则 Kubernetes 会阻止更新,新版本会一直处于 Pending 状态;这是因为我们在任何时刻都不允许出现没有(正在运行的) receiver 容器的场景。
Kubernetes 让扩展成为相当容易的事情。由于 Kubernetes 管理整个集群,你仅需在模板文件中添加你需要的副本数目即可。
这篇文章已经比较全面了,但文章的长度也越来越长。我计划再写一篇后续文章,在 AWS 上使用多节点、多副本方式实现扩展。敬请期待。
kubectl delete deployments --all kubectl delete services -all
各位看官,本文就写到这里了。我们在 Kubernetes 上编写、部署、更新和扩展(老实说,并没有实现)了一个分布式应用。
如果你有任何疑惑,请在下面的评论区留言交流,我很乐意回答相关问题。
希望阅读本文让你感到愉快。我知道,这是一篇相对长的文章,我也曾经考虑进行拆分;但整合在一起的单页教程也有其好处,例如利于搜索、保存页面或更进一步将页面打印为 PDF 文档。
Gergely 感谢你阅读本文。
via: https://skarlso.github.io/2018/03/15/kubernetes-distributed-application/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK