

SQL无法走索引的情况及解决思路
source link: https://www.linuxprobe.com/sql-solution-ideas.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
上次丁俊大师在社群上做了CBO优化器和坑爹案例的分享后,反响不是一般的强烈,但其中也有一部分同学表示太高大上了(我也是这样觉得的),消化起来相当有难度,于是便有了本文。绕开复杂的CBO优化器不说,本文将帮你理清那些因为SQL语句编写规范问题导致没有充分利用索引来大幅提升效率的使用场景。
因为数据库优化器不够智能,或者一些逻辑原因,导致SQL在比较适合走索引的情况下却无法正确利用索引。这时候,除了给数据库需要的统计信息之外,SQL语句本身还必须要给优化器足够多的额外有效信息,帮助优化器能够选择更好的执行计划。要让优化器正确选择需要的索引,要考虑两点:
- 如何避免优化器的限制
- 根据业务数据特点改写SQL语句
说明:这里说的走不了索引,是指走不了正常的RANGE SCAN,非(FAST) FULL INDEX SCAN。
SQL无法走索引常见的有如下8种情况:
- 统计信息不准确
- 索引列的值允许为NULL
- 谓词使用了不等于(<>, !=)
- LIKE前通配或全通配的查询
- 索引列使用了函数、数学运算、其它表达式等
- 使用了隐式类型转换
- 查询转换失败
- 其它语句逻辑原因
第一、二种情况在现实中比较常见,解决办法也相对比较简单,下面就不再作详细展开了。
解决方法:
- 如果不等条件之外的值不多,而且是确定的,可以改为等值或IN查询,比如status状态字段一般值类别很少;
- 如果不等条件之外的值很多,可以改为“> OR <”的形式,当然第2种方法包含了方法1。
举个例子,先构建测试场景:
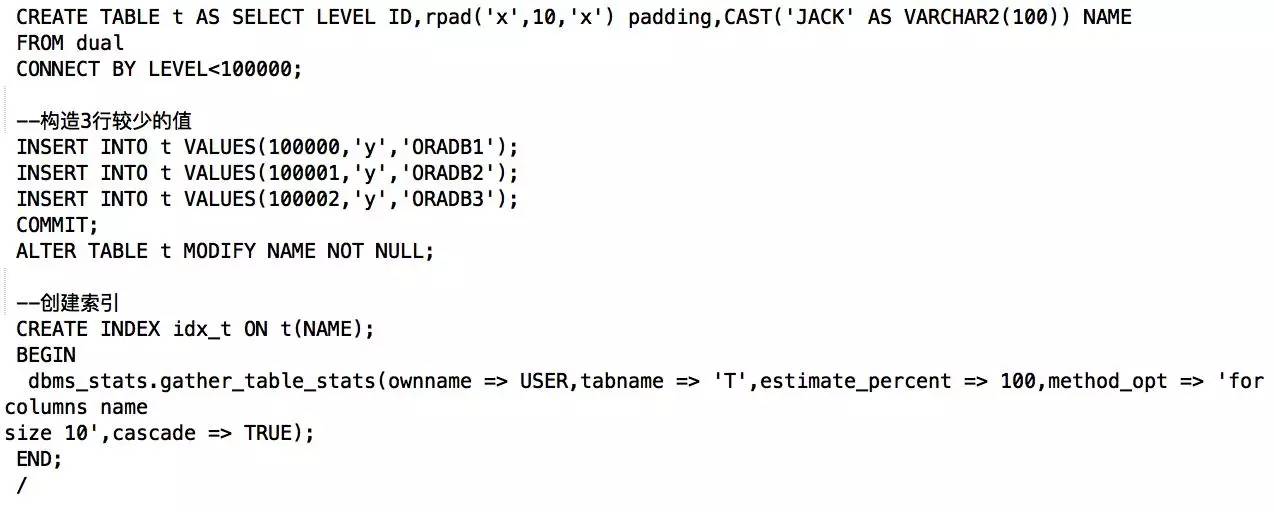
谓词使用<>,无法利用索引:
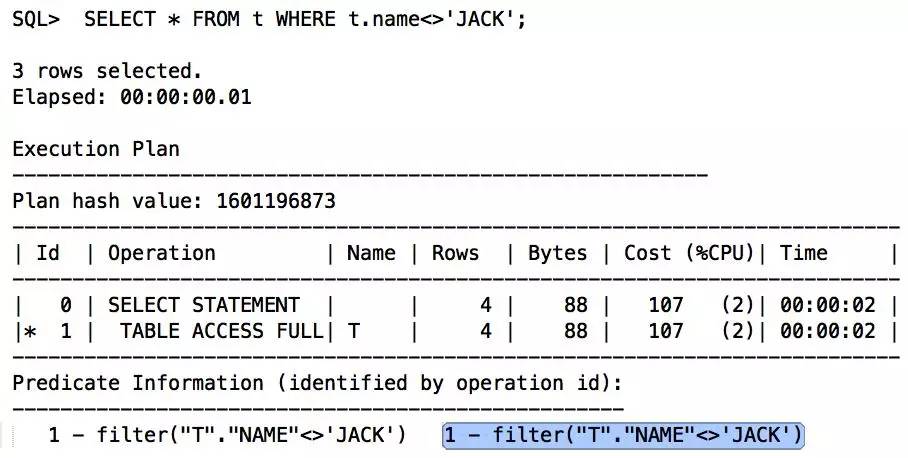
将<>改写为OR连接后,能够正确使用索引,走OR扩展:
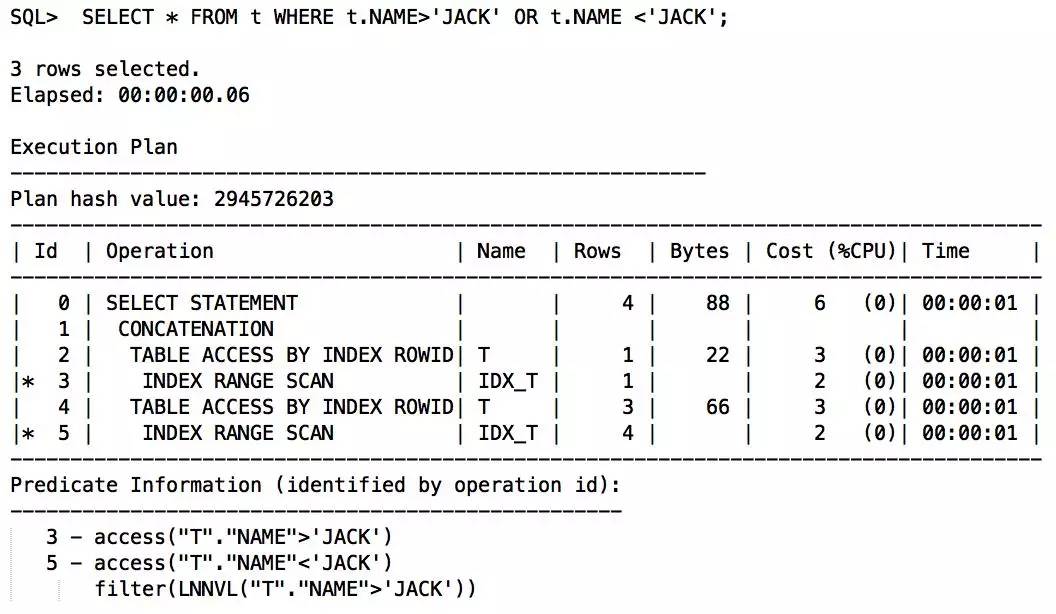
如果业务允许,改写为下列语句也是走索引的,不再演示。
SELECT * FROM t WHERE t.NAME IN (‘ORADB1′,’ORADB2′,’ORADB3’);
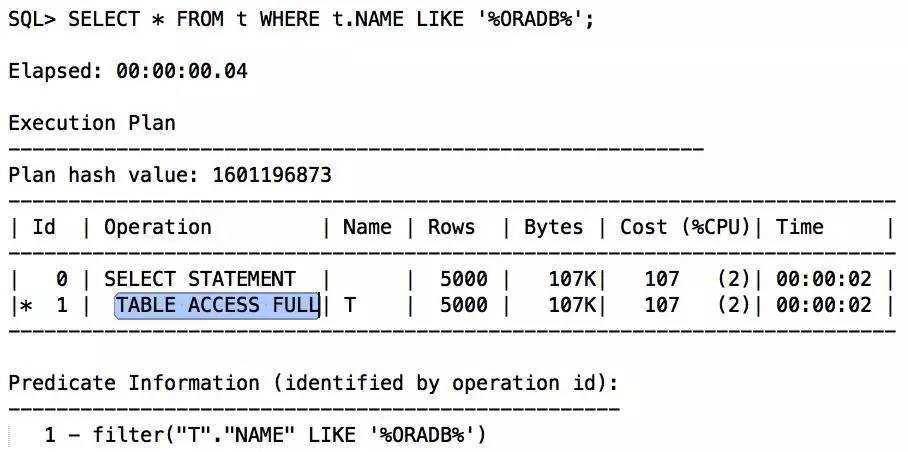
LIKE前通配或全通配的查询,走不了索引
解决方法,有如下三种:
(1)根据业务需求,是否可以把前通配去掉
原来全通配,无法走索引:
把前通配去掉,改为后通配,可以正常使用索引:
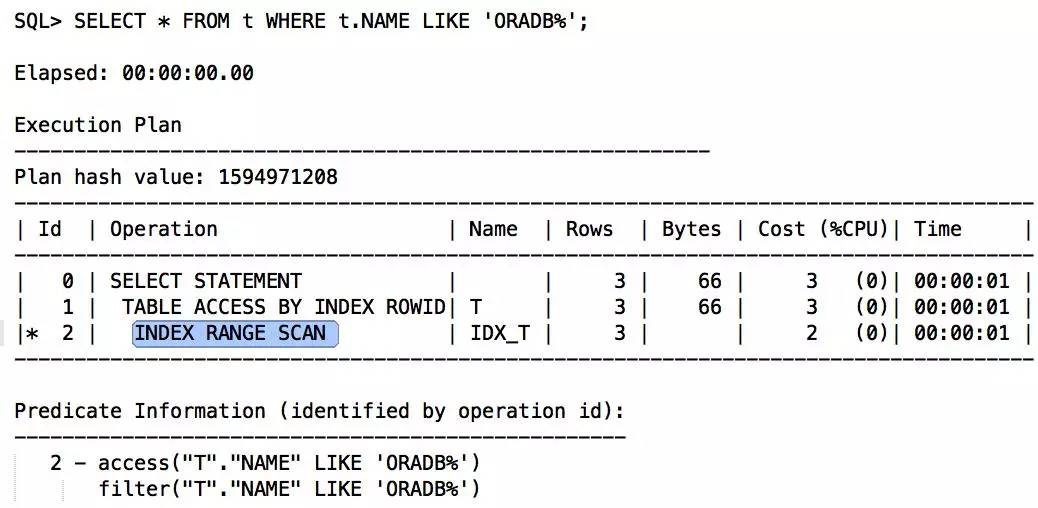
(2)和此LIKE一样的前通配或全通配的SQL有很多,此谓词的LIKE变化不大?如果是,考虑建立函数索引,否则对于全通配问题最好办法就是全文索引。
创建instr函数索引:
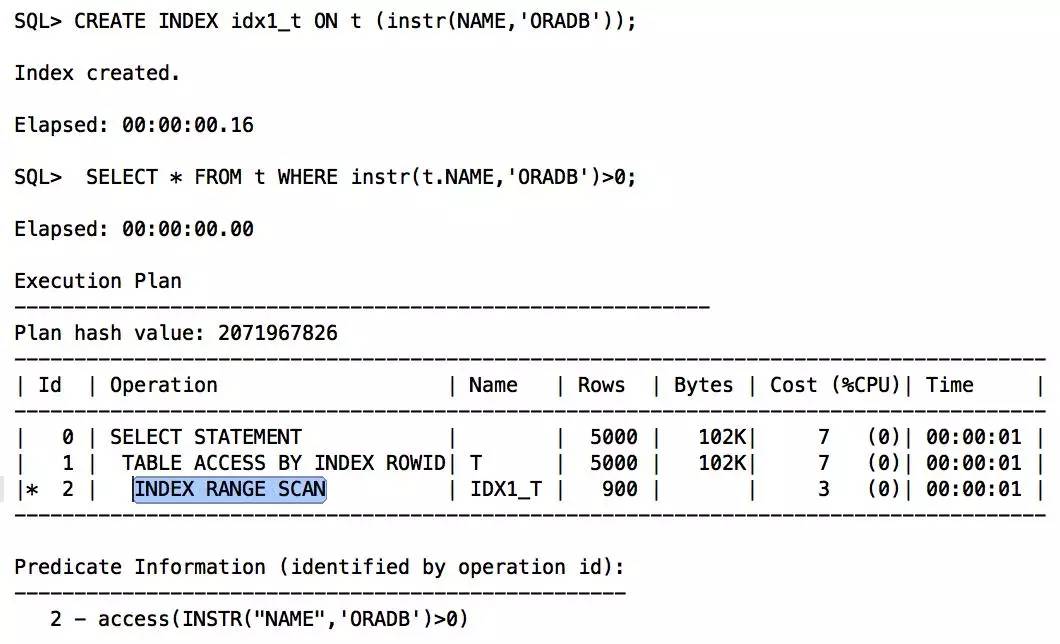
(3)如果只是前通配,可以使用reverse函数索引(不是翻转键索引)
原始语句:
SELECT * FROM t WHERE t.NAME LIKE ‘%ORADB1’;
创建reverse函数索引,并改写语句,注意查找值要倒序:
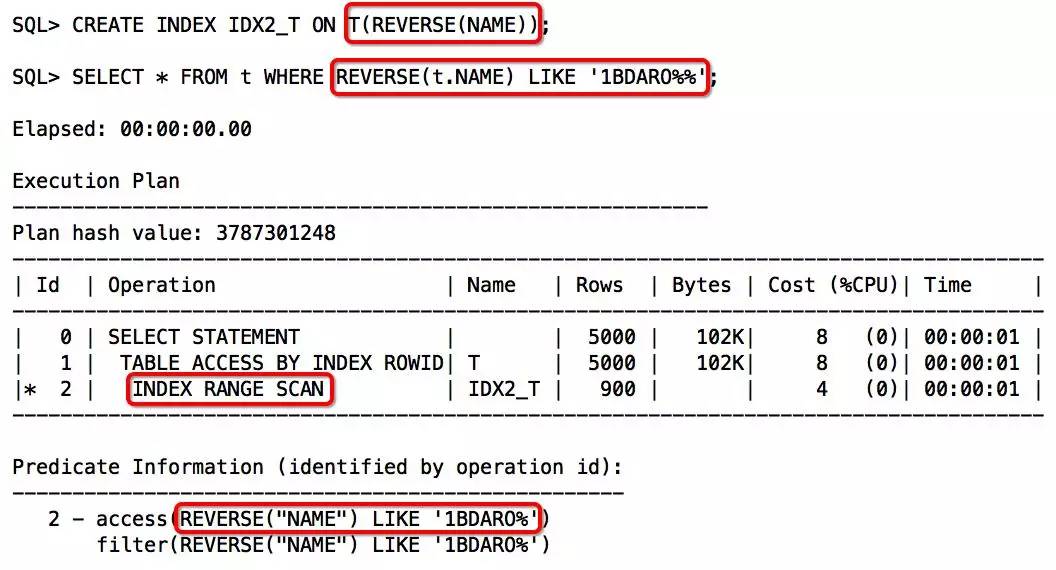
注意:如果通配查询的是中文,要注意使用REVERSE翻转条件值,因为REVERSE内部会按字节翻转的,正确写法如:
SELECT * FROM t WHERE REVERSE(t.name) LIKE REVERSE(‘数据’)||’%’;
否则查询出来的数据不对,将可能影响到业务的正常运行。
解决方法:去掉对索引列的相关运算,保持索引列纯净。
目前优化器对一些数学运算,还无法做很好的消除动作,所以对于索引列应该尽量保持纯净,否则可能无法用上正确的索引。
举例:
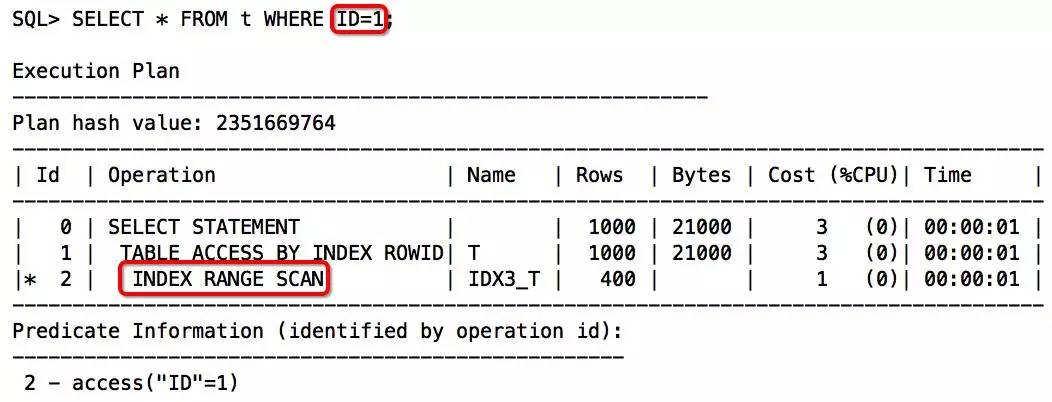
把语句的条件改写一下,将运算去掉:
以上例子只是简单的数学运算,可能的运算还有和其他列运算,比如where ID+ext_col…
记住一个原则:尽量保持索引列纯净。
解决方法:必须避免隐式类型转换,全部要求显式类型转换(非索引列),且避免对索引列进行类型转换(有函数索引除外)。如果类型不一致,不管是否发生自动类型转换,谓词的右值应该显式转换为与索引列保持一致(对于非索引列的运算也应该如此)。
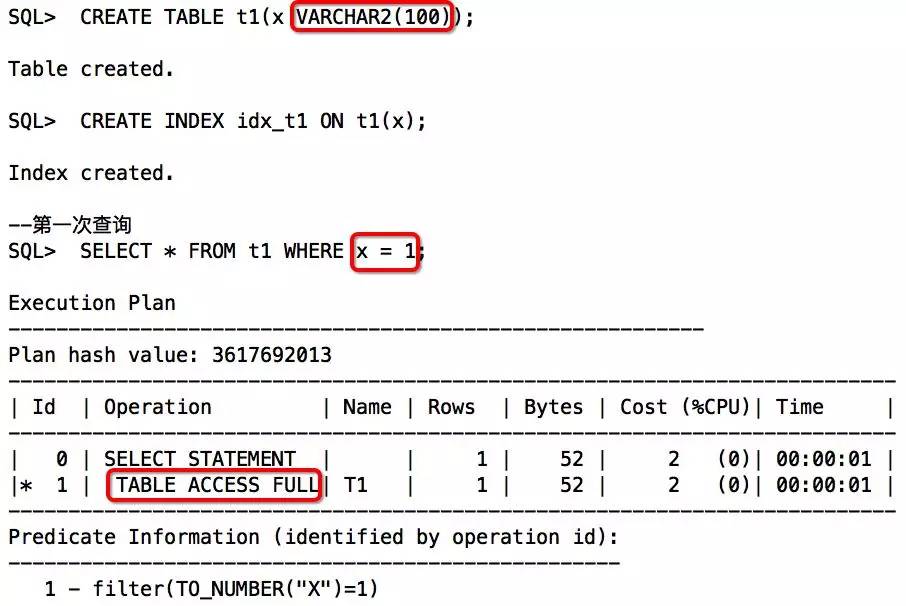
举例:
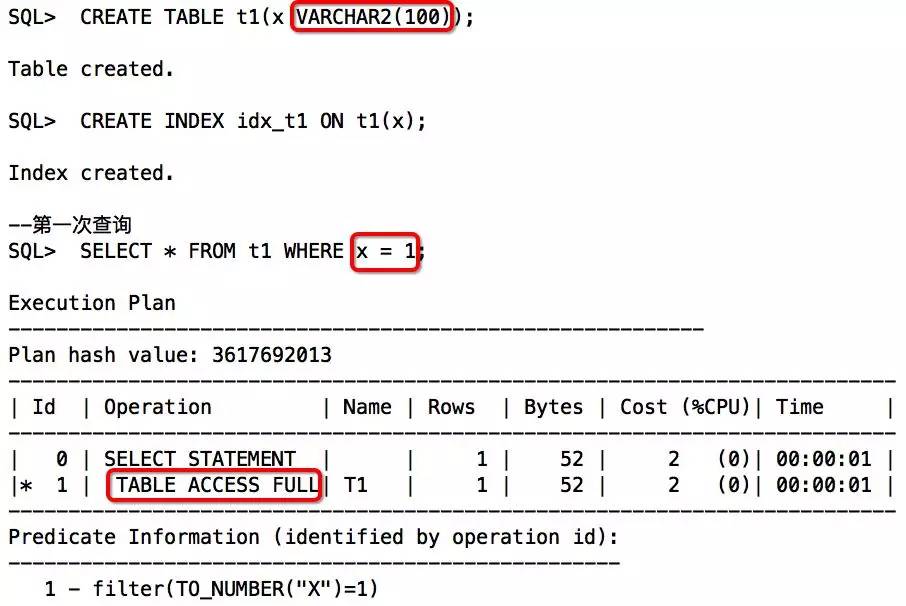
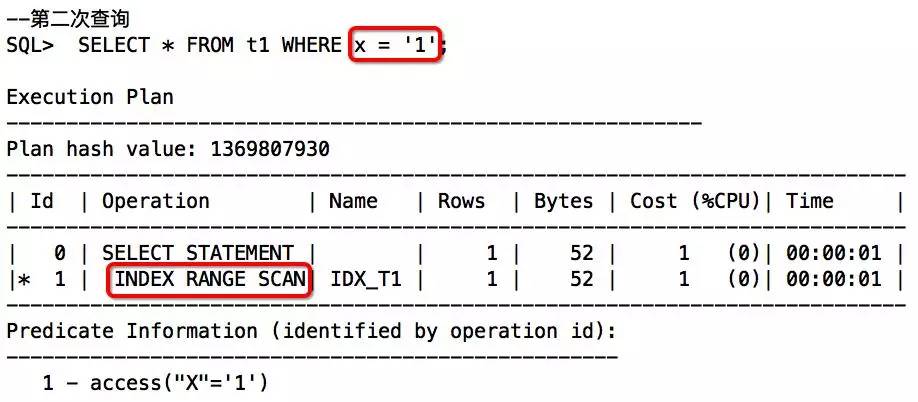
从以上两次查询对比来看,第一次查询发生了类型转换,可以通过执行计划中的谓词信息获知。通过分析发现,X因为是VARCHAR2,优先级比数值类型低,遇到数值类型,会TO_NUMBER隐式转换,所以索引失效。第二次查询,通过传入与索引列类型一致的字符串后,得以解决。
查询转换是非常复杂的过程,ORACLE CBO的查询转换有好几十种,比如CVM :complex view merging ,SU:subquery unnest, JPPD:JOIN PREDICATE PUSH DOWN等(在10053文件里都可以看到)。如果查询转换失败,那么必将影响后续优化器的一些操作,比如JPPD中JOIN谓词无法推入到视图中,那么很可能视图就无法走索引了。而且,查询转换有很多BUG,触发BUG需要找到原因,比如设置隐含参数、fix control等,或者改写SQL绕过BUG。如下例所示:

其中AB_XRTOFFREC_201703是UNION ALL查询组成的视图,这个查询在10.2.0.4上很正常,升级到11.2.0.4后执行计划显示不走索引,性能非常差。
在10g中的执行计划:
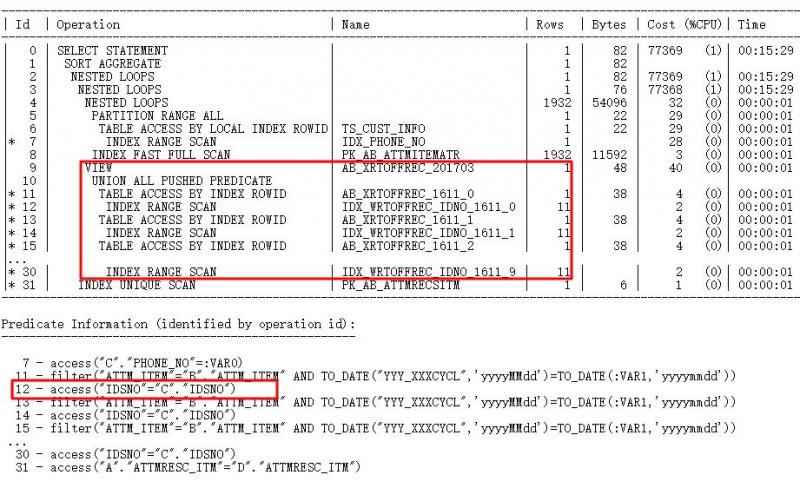
在11g中的错误执行计划:
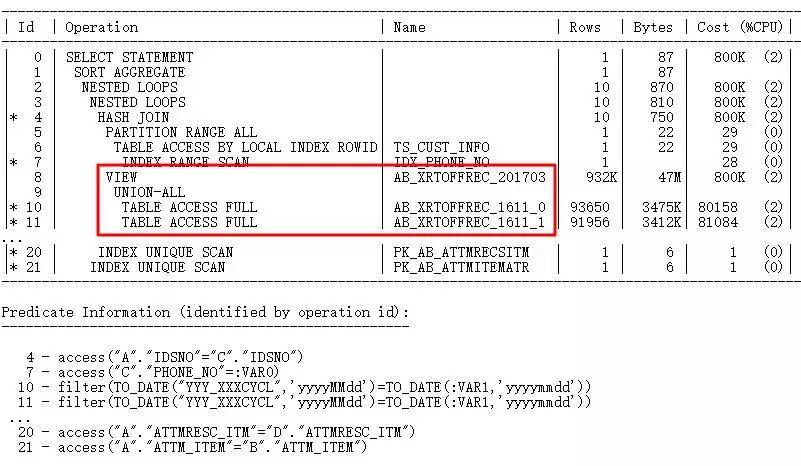
通过收集统计信息都无效,将优化器降级到10.2.0.4即有效。很显然,这是引入了BUG或者新的限制。一旦遇到这种是BUG或限制导致的,可以通过10053跟踪文件或者SQLT来进行分析。对于这条语句无法走JPPD查询转换,在10053中就可以找到原因:

然后在MOS中查看得知是BUG:9380298,默认开关关闭。

ORACLE针对这样的查询,为了防止遇到笛卡尔积,默认把修复BUG的补丁关闭了。显然通过设置_fix_control参数打开9380298 fix即可。
举一个典型的例子,先准备测试表,并在其上创建一个组合索引:

查询需求:查找创建时间是2013年的,并且最后ddl时间比创建时间大1天以上的对象。
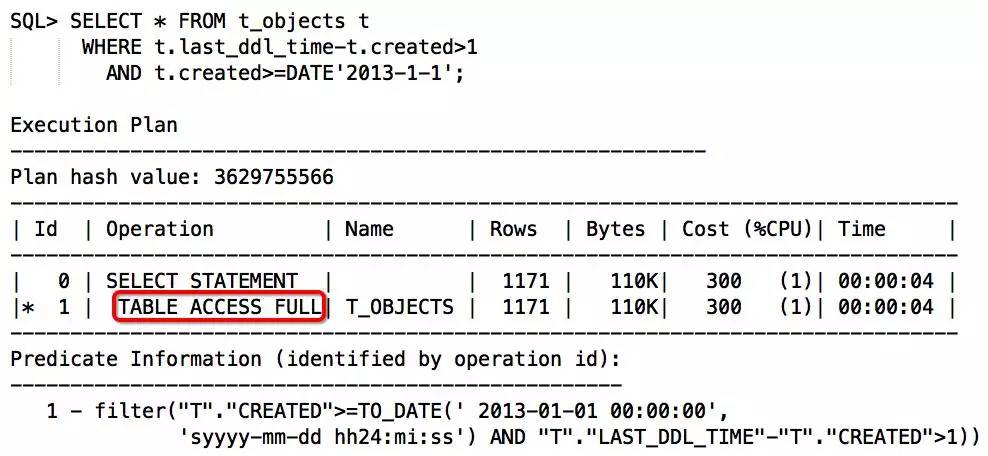
这个索引是组合索引,上面的语句对前导列进行了运行,也不符合走index skip scan的条件,所以,走FULL TABLE SCAN。那么是否可以通过逻辑改写走索引呢,基于保持索引列纯净的原则,将create_date移到右边,语句如下:
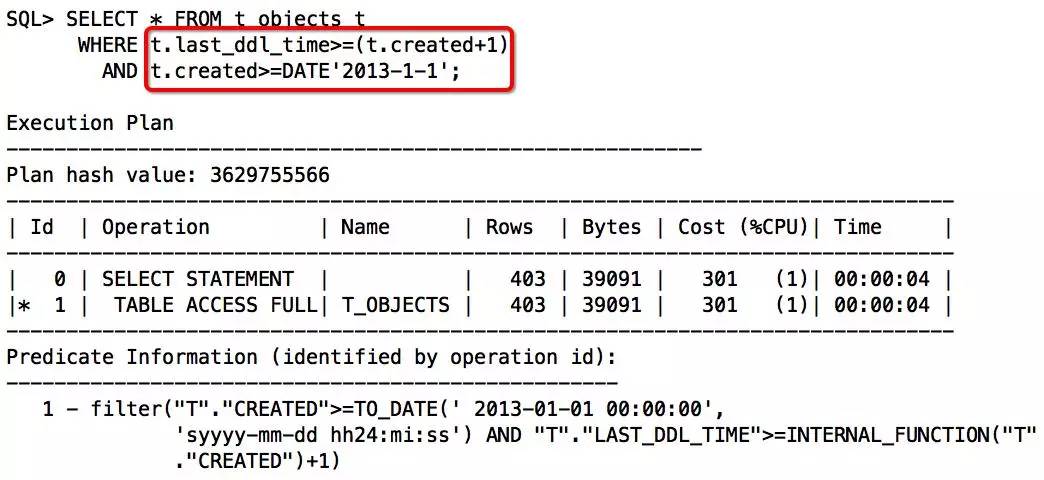
改写后发现,还是没有走索引,因为Oracle认为前导列右边的created不固定,无法从指定索引处查找。通过分析得知,Oracle谓词传递有一定限制,create_date+1无法做谓词传递给last_ddl_time。再次改写:
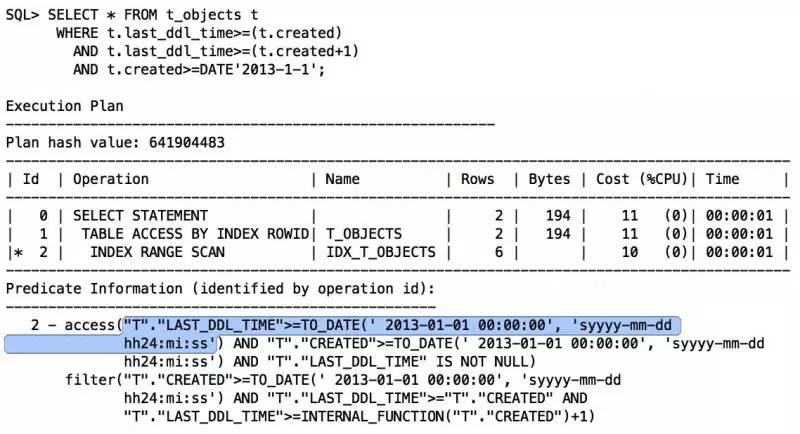
此时Oracle知道将谓词传递给last_ddl_time了,T.LAST_DDL_TIME>=TO_DATE(‘ 2013-01-01 00:00:00’, ‘syyyy-mm-dd hh24:mi:ss’)。当然,也可以手动谓词传递,last_ddl_time肯定大于等于DATE’2013-1-2′:
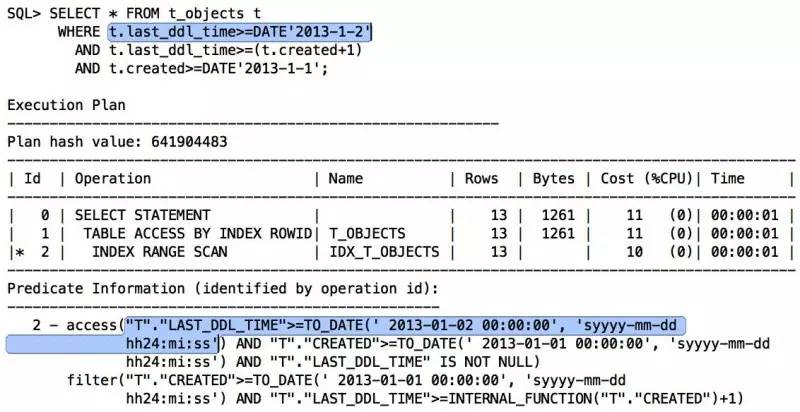
还未完,我们继续往下看:
如果查询条件中无t.created>=DATE’2013-1-1’,即如下面语句:
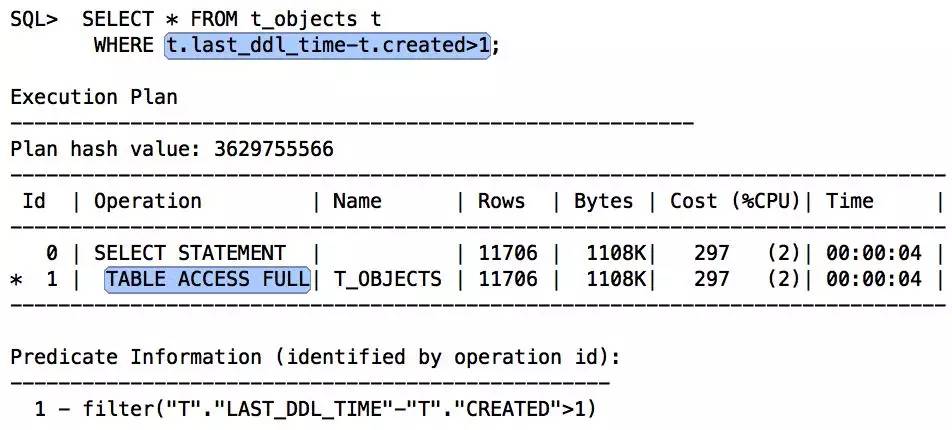
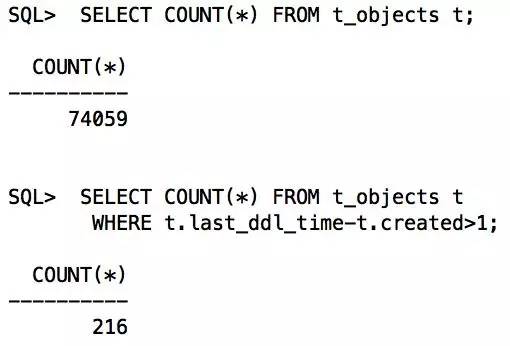
–由此两数据比较可知,应该走索引更佳。因为没有其他过滤条件,可以考虑建立函数索引:
SQL> CREATE INDEX idx1_t_object ON t_objects(last_ddl_time-created);
–注意收集直方图,因为分布不均
SQL> exec dbms_stats.gather_table_stats(ownname => USER,tabname => ‘t_objects’,estimate_percent => 100,method_opt => ‘for all indexed columns’,cascade => TRUE);

当然,对于两个都是范围的查询,这里只能通过一个列来轮询索引,先做access,再做filter。
SQL语句的逻辑改写很重要,往往通过逻辑改写就能改变SQL的执行计划,从不好的计划到好的计划,比如semi join,anti join与or,往往走FILTER导致执行计划较差,这时候就需要通过逻辑等价改写。逻辑等价改写往往需要掌握一些集合的知识,比如NOT (A AND B)==NOT A OR NOT B,NOT (A OR B)==NOT A AND NOT B等。
SQL有索引而不走索引的情况还有很多,比如在DBLINK查询中,可能走不了索引,这时候需要通过driving_site hint或者远程库建立视图等方式解决等,需要综合从语法语义、索引选择性、索引访问特点等多方面进行分析。
上面说到的问题,说到底都是不遵守数据库开发规范的问题。说到数据库开发规范,估计很多企业都有制定对应的规范及要求,但说到落地执行情况,这个就比较困难了。如果企业在意旨上是期望开发人员去学懂规范,然后学以致用,就有点太理想化了。于是,为了保证开发人员真的是按照数据库开发规范来编写代码,很多企业就在应用上线前增加了一道SQL上线审核的工序。
说到SQL上线审核,关键要解决三个问题:
1、如何在上线的应用版本中发现新增的SQL语句;
2、新增SQL存在哪些问题,如何快速准确的定位;
3、对于问题SQL,如何快速提供优化方案。
这三个问题,是一环扣一环的,解决不了前面的问题,就无从解决后面的问题。然而,应用系统SQL众多,如果单靠人工,难度是很大的,专家资源投入就更不说了,显然不能满足当今IT系统高速发展的需要。
这里跟大家分享我们在这方面的一些实践和成果。通过结合多年的运维和优化经验,我们自主研发了SQL审核工具,不仅可以自动化完成SQL上线审核,还可以做到SQL的性能监控和自动优化,达到SQL全生命周期管理的效果。对于SQL上线审核,我们将开发规范规则化后落到SQL审核平台,内置了4个维度、200多种常见的审查规则,还支持灵活的按需添加规则。同时,审查的不只是SQL语句本身,还包括了对表的模型设计、索引的构建。
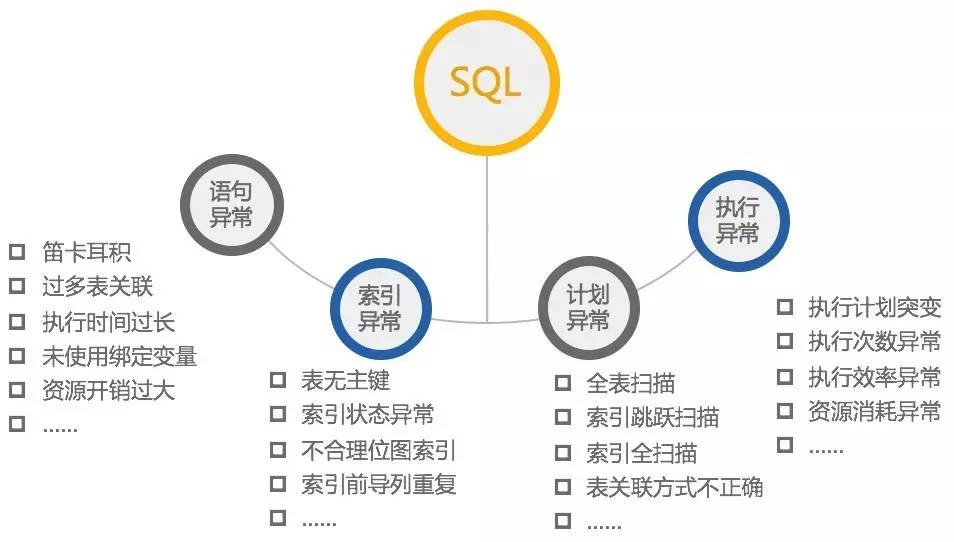
在应用新版本上线前,通过SQL审核平台,自动分析出版本的新增SQL,基于以上规则对新增SQL进行审查,并自动提供优化建议,可生成可视化的报表和详细报告。不管是DBA还是开发人员都可以基于此平台,对问题进行确认和解决,实现系统优化前移、提升应用版本质量的目标。
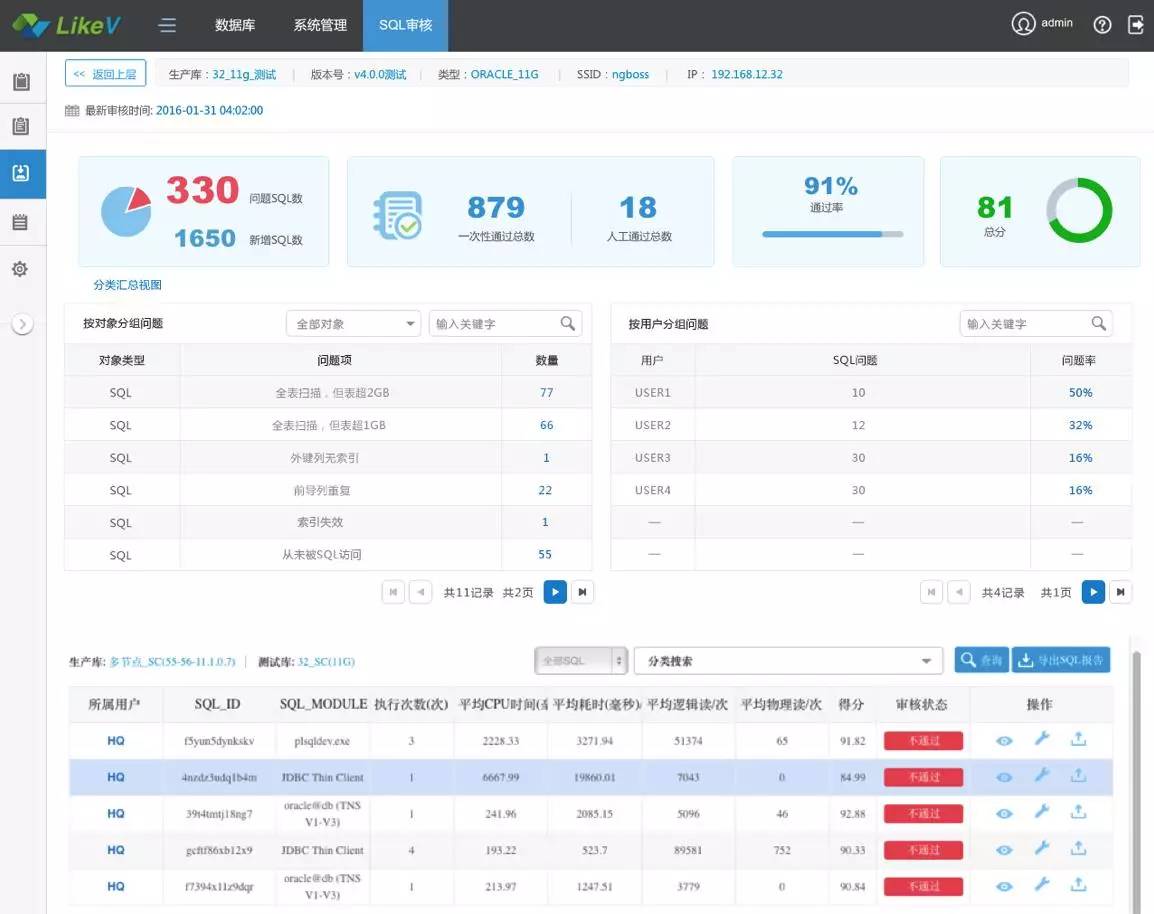
本文主要和大家分享了SQL无法走索引的一些常见情景及解决方法,当然,SQL的规范化使用是十分重要的,SQL的优化也不仅仅局限于索引的优化。所以,只有平时多积累,结合理论多实践,遇到问题时才能运筹帷幄,对症下药、药到病除。另外,企业在IT建设中要重视开发规范的落地执行,必要时使用合适的工具,在加速IT环境建设效率的同时,还能兼顾到IT系统的建设质量,做到两不误。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK